La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2010/11/03/checkpoint_completion_target/
The translation may contain errors.
Arrancando nuevas series del blog - explicación de varios parámetros de configuración.
Yo no seguiré por supuesto una programación u orden - si yo hubiera tenido que hacerlo - sería mi trabajo, y de esta manera - es divertido.
El primer parámetro de configuración sobre el que es escribir es checkpoint_completion_target.
Primero, vamos a pensar acerca de qué es el checkpoint.
Como tú tal vez sabes Postgresql mantiene cache de páginas (bloques de disco de 8kB (por defecto)) en RAM. Para hacerlo disponible a todos los backends (N. de T.: procesos en segundos plano), es almacenado en shared_buffers, y está (normalmente) tomando la mayoría de shared_buffers.
Si Pg necesita hacer algo con una página dada, comprueba si está en shared_buffers, y si no - la carga (haciendo alguna lógica para asegurar que no excederá el tamaño de shared_buffers añadiendo la nueva página).
Esto también ocurre en las escrituras.
Cuando tú escribes algo (piensa: insert, update, delete) el cambio no es escrito a la tabla. En cambio es escrito a estas páginas en memoria.
Ahora por supuesto hay una pregunta - ¿qué ocurre si hubiera una caída del servidor? ¿Como los datos están en ram yo lo perderé? No. Porque los datos están también escritos a "WAL". WAL son aquellos ficheros de 16MB en el directorio pg_xlog. Estos son (virtualmente) nunca leídos, y sólo contienen la lista de cambios a páginas.
Así, el flujo se parece como esto: tú haces un insert. Postgresql carga la página a memoria (si ella no estuvo allí anteriormente), la modifica, y escribe la información sobre la modificación al WAL. El cambio no es aplicado a los ficheros de la tabla real.
Ahora - después de algún tiempo - hay un montón de páginas modificadas en memoria, que no están aplicadas a la tabla. Y esto es cuando CHECKPOINT ocurre. Hay alguna lógica cuando el checkpoint es emitido (yo escribiré sobre ello en algún post del blog más adelante), pero por ahora, la parte importante es: cuando el checkpoint ocurre, todas las páginas modificadas (también llamadas sucias (N. del T.: dirty en inglés)) son escritas a la actual tabla y a los ficheros de índices.
¿Hasta aquí todo bien? Eso espero.
Ahora - el tamaño del checkpoint es por supuesto variable, pero depende del tamaño de shared_buffers, y cómo de a menudo tú tengas checkpoints, y cómo de intensiva en escritura es tu aplicación.
Imaginemos, que tú tienes un servidor con 100GB de shared_buffers (es un montón, pero no inaudito). Y es intensivo en escritura. Así, cuando el checkpoint ocurre, podría necesitar volcar 100GB de datos a disco. Más o menos a la vez. Es un problema. Porque es un gran pico de I/O (N. del T.: I/O es input/output, E/S entrada/salida), e influirá directamente en el rendimiento de concurrencia de las consultas normales.
Esto es donde checkpoint_completion_target aparece.
Generalmente es un parámetro que hace que Postgresql intente escribir los datos más lento - para finalizar en el tiempo checkpoint_completion_target * checkpoint_timeout. Normalmente tú tienes checkpoint_timeout configurado a 5 minutos (a menos que tú lo modificaras), y el checkpoint_completion_target por defecto es 0.5. Esto significa que Postgresql intentará hacer que el checkpoint tome 2.5 minutos - para hacer la carga de I/O más lenta.
Vamos de vuelta a nuestro ejemplo. Nosotros tenemos 100GB de datos para ser escritos a ficheros. Y mi disco puede mantener 1GB por segundo de escrituras (es un gran servidor con un gran I/O). Cuando haciendo el checkpoint normal (la forma que había antes de 8.3), esto tomaría 100 segundos al 100% de utilización del ancho de banda para escribir los datos.
Pero - con checkpoint_completion_target configurado a 0.5 - Postgresql intentará escribir los datos en 2.5 minutos - así efectivamente usando sólo ~ 700 MB/s, y dejando 30% de capacidad de I/O para otras tareas. Es una gran beneficio.
El problema con este enfoque es relativamente simple - como el checkpoint toma mucho tiempo para escribir, los segmentos wal obsoletos, viejos, permanecen más tiempo en el directorio pg_xlog, que crecerá más.
En la época de 8.2, el número de ficheros en el directorio pg_xlog iba habitualmente hasta 2 * checkpoint_segments + 1.
Ahora, puede ser estimado para ser ( 2 + checkpoint_completion_target ) * checkpoint_segments + 1.
Si tú leiste los párrafos de arriba con atención al detalle tú viste que yo usé la palabrá "intentar". La razón es muy simple - el ancho de banda afectivo de I/O es variable, así que no hay garantía. Así, vemos cómo realmente trabaja.
Para las pruebas, yo uso mi máquina de pruebas, con una configuración que coloca datos, xlogs y logs de consultas (útil para pruebas para bloqueos/ralentizaciones) en particiones separadas.
Mientras poner estos en particiones separadas de el mismo disco no incrementará el rendimiento, me permitirá monitorizar exactamente qué ocurre en cada una de las particiones mientras las pruebas.
Con estas 3 particiones, yo las dispondré así:
sda1 - swap, no debe de ser usado, así que no es importante.
sda2 - filesystem raiz (N. del T.: root), y lugar donde los logs de las consultas y de iostat están almacenados
sda3 - $PGDATA
sda4 - pg_xlog - segmentos wal
Para probar Pg, yo estoy usando el programa pgbench estándar, con escala de 35 (-s 35 que significa que la base de datos generada, sin ningún test hecho, es ~ 550MB).
Yo podría haber usado una base de datos más grande, pero como pgbench escribe por toda la base de datos, yo quiero asegurarme que las escrituras a las tablas ocurren sólo debido a los checkpoint, y no porque algún shared_buffer tiene que ser liberado para hacer lugar a otro.
Dado que my HDD mantiene ~ 50MB/s de escrituras, yo puedo asumir que el checkpoint con checkpoint_completion_target = 0 debe de tomar ~ 11 segundos.
Configuración usada:
shared_buffers = 1024MB - Yo necesito grandes shared buffers para ser capaz de observa los tiempos de checkpoint.
log_checkpoints = on – bien, yo necesito saber cuándo los checkpoit ocurren
checkpoint_segments = 30 - sólo un número de cuántos segmentos WAL pueden ser llenados antes de que checkpoint sea forzado
checkpoint_timeout = 5min - cada cuanto tiempo hacer checkpoint de los datos
checkpoint_warning = 5min - si el checkpoint ocurre más a menudo que esto (lo cual es lo mismo que el timeout) - avisar sobre ello en los logs. Esto es para ver la situación cuando nosotros tenemos demasiados pocos checkpoint_segments.
log_line_prefix = ‘%m %r %u %d %p ‘ – para tener los logs de consultas de pg bien prefijados con la información importante
log_min_duration_statement = 5 - yo no quiero dejar registro de todas las consultas - ya que habrá muchas. Yo sólo quiero registrar aquellas que sobrepasen los 5ms - así yo veré si habrá picos en el número de esas consultas en los checkpoints.
Yo hice 5 pruebas, con checkpoint_completion_target siendo: 0, 0.3, 0.6, 0.9 y 1.
Esta es la utilización de IO de la partición PGDATA con checkpoint_completion_target = 0:

¿Qué es el %util? Desde el comando man iostat:
Porcentaje de tiempo de CPU durante el que las peticiones de I/O fueron enviadas al dispositivo (utilización del ancho de banda del dispositivo). La saturación del dispositivo ocurre cuando este valor es cercano al 100%.
Y, basado en el gráfico de arriba, yo inmediatamente vi que mi conjunto de datos de pruebas es demasiado grande, ya que el checkpoint tomó la mayoría del tiempo.
Así, yo rehice la prueba, con un conjunto de datos incluso más pequeño - escala 15, tamaño de la base de datos - ~ 300MB).
Resultados
checkpoint_completion_target = 0
Pgbench estuvo poniendo la carga en la base de datos entre 14:57:34 y 15:09:34. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada
Esta es la utlilización de IO de la partición de PGDATA:

¿Qué es el %util? Desde el comando man iostat:
Porcentaje de tiempo de CPU durante el que las peticiones de I/O fueron enviadas al dispositivo (utilización del ancho de banda del dispositivo). La saturación del dispositivo ocurre cuando este valor es cercano al 100%.
Rendimiento de escritura:

y finalmente, un valor muy importante - await
El tiempo medio (en milisegundos) para peticiones I/O enviadas al dispositivo para ser servidas. Esto incluye el tiempo gastado por las peticiones en la cola y el tiempo gastado sirviéndolas.

checkpoint_completion_target = 0.3
Pgbench estuvo poniendo la carga en la base de datos entre 15:29:44 y 15:41:44. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



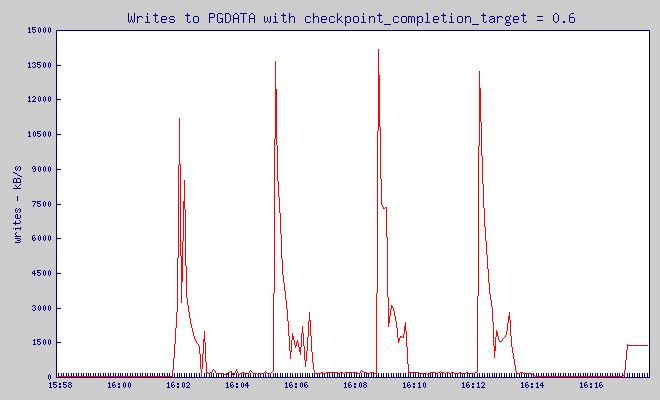
checkpoint_completion_target = 0.6
Pgbench estuvo poniendo la carga en la base de datos entre 16:01:55 y 16:13:55. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada


checkpoint_completion_target = 0.9
Pgbench estuvo poniendo la carga en la base de datos entre 16:34:08 y 16:46:08. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



checkpoint_completion_target = 1
Pgbench estuvo poniendo la carga en la base de datos entre 17:06:21 y 17:18:22. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada

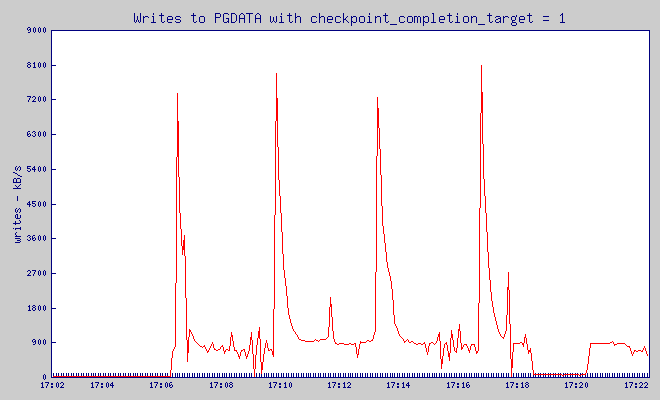

Estos gráficos son muy dentados, pero yo esper que tú puedas ver que mientras checkpoint_completion_target escribió en un gran pico que uso 40MB de tráfico de escritura, con todos los otros valores de checkpoint_completion_target el pico de escritura fue mucho más pequeño.
¿Y cómo se está relacionando al número de consultas lentas? Como tú tal vez recuerdes - yo registré cada consulta que tomó más de 5ms. Basado en el registro de consultas, yo puede ver cómo de frecuente nosotros tuvimos consultas lentas.
| cct | número de consultas ejecutándose más de | ||||
|---|---|---|---|---|---|
| 100ms | 200ms | 300ms | 400ms | 500ms | |
| 0 | 122 | 52 | 51 | 44 | 37 |
| 0.3 | 92 | 41 | 37 | 36 | 31 |
| 0.6 | 122 | 34 | 29 | 28 | 23 |
| 0.9 | 164 | 30 | 18 | 17 | 16 |
| 1 | 173 | 23 | 13 | 13 | 12 |
Como tú puedes ver incrementar checkpoint_completion_target ofrece un visible decremento en el número de consultas que tomaron más de 200ms. El rango (100,200) ms es diferente, pero podemos ver que las consultas más largas, y más perturbadoras, son mucho menos comunes que sucedan con un mayor checkpoint_completion_target.
Así, ¿hay algún inconveniente para incrementarlo?
Bien, para los que empiezan - puede inflar el directorio pg_xlog, de acuerdo a la fórmula que yo traje al comienzo del post.
Y segundo - no siempre funciona - si tus shared_buffers son demasiado grandes, y tú escribe a ellos demasiado - pg tendrá que hacer checkpoint virtualmente todo el tiempo - tal y como ocurrió en el primer gráfico que yo mostré, así cualquier "ralentización" simplemente no funcionará.
Finalmente - recuerda que el será más largo el tiempo desde el último checkpoint en caso de apagado forzado (piensa: corte de energía) - más largo tiempo llevará la recuperación. Y como un checkpoint_completion_target más largo significa checkpoint más lentos - esto también te hace (de media) ir más lejos del último checkpoint - así haciendo la eventual recuperación más larga.
Dejando de lado estos hecho - yo no puedo realmente pensar niguna razón para no hacerlo a 0.9 (yo no iría con 1.0, para evitar la situación cuando el siguiente checkpoint es pospuesto, debido a que el previo no ha sido hecho aún) como un cambio básico en el ajuste de Postgresql.
No hay comentarios:
Publicar un comentario