Esta entrada es una traducción de https://www.depesz.com/2011/07/14/write-ahead-log-understanding-postgresql-conf-checkpoint_segments-checkpoint_timeout-checkpoint_warning/
La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2011/07/14/write-ahead-log-understanding-postgresql-conf-checkpoint_segments-checkpoint_timeout-checkpoint_warning/
The translation may contain errors.
Aunque hay algunos documentos sobre ello, yo decidí escribir sobre ello, en tal vez un lenguaje más accesible - no como un desarrollador, sino como un usuario de Postgresql.
Algunas partes (partes bastante grandes) fueron descritas en uno (N. del T.: traducción al español) de mis anteriores posts, pero yo intentaré concentrarme en WAL en sí mismo, y mostraré un poco más aquí.
Antes de que yo vaya sobre cómo es escrito, y cómo comprobar varias cosas, primero vamos a intentar pensar una pregunta simple: ¿por qué existe esta cosa? ¿Qué hace?
Imagina que tú tienes un fichero de 1GB, y que tú quieres cambiar 100KB de él, desde un desplazamiento (offset) definido.
Teóricamente es sencillo - abre el fichero para escribir (sin opción de sobreescribir), haz un fseek() a la posición apropiada, y escribe los nuevos 100KB. Después cierra el fichero, y abre una cerveza - trabajo hecho.
¿Pero lo está? ¿Qué ocurrirá si la energía se va mientras se está haciendo la escritura? ¿Y si tú no tienes UPS?
Esta es realmente una muy mala situación - asumamos que ocurrió en medio del proceso. Tu programa fue detenido (bien, la máquina fue apagada), y los datos en el disco contienen mitad de datos antiguos y mitad de datos nuevos.
Por su puesto tú podrías argumentar que esto es por lo que nosotros tenemos UPSes, pero realmente es un poco más complicado - varios discos o controladoras de almacenamiento tienen cache de escritura, y pueden mentir al sistema operativo (el cual entonces miente a la aplicación) que los datos han sido escritos, mientras que están en caché, y entonces el problema puede ocurrir de nuevo.
Así, la solución que tiene que ser encontrada asegurará que nosotros tendremos o los datos nuevos, o los datos viejos, pero no una mezcla de ambos.
La solución aquí es relativamente simple. Aparte de este fichero de datos de 1GB, almacena un fichero adicional, que nunca es sobreescrito, sólo es añadido. Y cambia tu proceso a:
abre el fichero de registro (log), en modo añadir
escribe al fichero de registro la información "escribiras estos datos (aquí van los datos) a este fichero (ruta) en el desplazamiento (desplazamiento)"
cierra el fichero de registro
asegúrate que el fichero de registro es realmente escrito a disco. Llama a fsync() y espera que los discos lo hagan correctamente
cambia el fichero de datos normalmente
marca la operación en el fichero de registro como hecha
La última parte puede ser simplemente hecha almacenando la localización de alguna parte del último cambio aplicado del fichero de log.
Ahora. Pensemos sobre el fallo de energía. ¿Qué ocurrirá si el fallo de energía ocurriera cuando se está escribiendo el fichero de registro? Nada. Los datos en el fichero real no están dañados, y tu programa tiene que ser bastante inteligente para ignorar las entradas de registro que no están completamente escritas. ¿Y qué ocurrirá si la caída de energía ocurriera durante el cambio de datos en tu fichero real? Es simple - en el siguiente arranque de tu programa, tú compruebas el registro para cambios que deben de ser aplicados, pero no lo están, y tú los aplicas - cuando le programa es arrancado el contenido del fichero de datos está roto, pero es arreglado rápido.
¿Y si la energía se fuera cuando se está marcando la operación como hecha? Sin problema - en el siguiente arranque la operación será simplemente rehecha.
Gracias a esto nosotros estamos (razonablemente) seguros de tales cosas. Esto además tiene otros beneficios, pero esto vendrá más adelante.
Así, ahora que nosotros sabemos cuál es el propósito del WAL (en caso de que no esté claro: protege tus datos de fallos de hardware/energía), pensemos sobre cómo.
Postgresql use las llamadas "páginas" (pages). Todas las cosas aparte, la página es simplemente 8KB de datos. Esto es por lo que los ficheros de tabla/índice tienen siempre tamaños divisibles por 8192 (8KB) - tú no puedes tener una tabla que sea 10.5 páginas en tamaño. Es de 11 páginas. No todas las páginas están llenas. No todas son incluso garantizadas para ser usadas (ellas pueden contener datos que fueron eliminados).
Todas las operaciones de IO usan páginas. Es decir, para conseguir el valor INT4 de una tabla, postgresql lee 8KB de datos (al menos).
Así, ¿qué ocurre cuando tú INSERTAS (INSERT) una nueva fila? Primero postgres encuentra a qué página la pondrá. Puede ser una nueva página creada si todas las páginas de la tabla están completas, o puede ser alguna otra página si hay espacio libre en ellas.
Después de que la página ha sido elegidas Postgres la carga a memoria (shared_buffers), y hace los cambios allí. La información de todos los cambios es registrada a WAL, aunque esto es hecho mediante un simple "write()" (sin llamar a fsync, aún), así esto es muy rápido.
Ahora, cuando tú emites un COMMIT; (que podría ocurrir automáticamente si es una conexión con auto-commit), Postgres realmente hace fsync() al WAL. Y esto es todo. Los datos no están escritos a tu fichero de tabla.
En este momento, los cambios que tú quisiste (la nueva fila) están en 2 lugares:
copia modificada de la página de la tabla en shared_buffers
registro en WAL con la información sobre el cambio
Todas las escrituras al WAL son hechas no por backends (N. del T.: procesos en segundos plano) individuales, sin por procesos especializados - wal write, el cual tú puedes ver por ejemplo aquí:
=$ ps uxf
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
pgdba 25473 0.0 0.0 112552 2104 ? S 01:16 0:00 sshd: pgdba@pts/8
pgdba 25474 0.0 0.0 28000 6704 pts/8 Ss 01:16 0:00 \_ -bash
pgdba 25524 0.0 0.0 20520 1148 pts/8 R+ 01:16 0:00 \_ ps uxf
pgdba 7366 0.0 0.0 67716 7492 ? S Jul13 0:00 /home/pgdba/work/bin/postgres
pgdba 7368 0.0 0.0 25308 888 ? Ss Jul13 0:01 \_ postgres: logger process
pgdba 7370 0.5 0.2 67936 36176 ? Ss Jul13 0:55 \_ postgres: writer process
pgdba 7371 0.0 0.0 67716 2072 ? Ss Jul13 0:08 \_ postgres: wal writer process
pgdba 7372 0.0 0.0 68824 5588 ? Ss Jul13 0:00 \_ postgres: autovacuum launcher process
pgdba 7373 0.0 0.0 27404 900 ? Ss Jul13 0:00 \_ postgres: archiver process last was 000000010000000800000057
pgdba 7374 0.0 0.0 27816 1340 ? Ss Jul13 0:01 \_ postgres: stats collector process
Gracias a esto no hay bloqueos en las escrituras al WAL, así de simple, añadiendo en plano datos.
Ahora, si nosotros continuáramos el proceso durante un tiempo largo, nosotros tendríamos un montón de páginas modificadas en memoria, y montones de registros en WAL.
Así, ¿cuándo están los datos escritos a las páginas de disco reales de las tablas?
Dos situaciones:
swap (intercambio) de páginas
checkpoint
El intercambio de páginas es un proceso muy simple - asumamos que nosotros teníamos shared_buffers configurado a 10, y todos estos buffers están tomados por 10 páginas diferentes, y todas están modificadas. Y ahora, debido a la actividad del usuario Postgres tiene que cargar otra página para obtener datos de ella. ¿Qué ocurrirá? Es simple - una de las páginas será desalojada de la memoria, y la nueva página será cargada. Si la página que fue eliminada estaba "sucia" ("dirty") (lo que significa que había cambios en ella que no habían sido guardados aún al fichero de tablas), será primero escrita al fichero de tabla.
El checkpoint es mucho más interesante. Antes de que vayamos dentro de lo que es, pensemos sobre el escenario teórico. Tú tienes una base de datos que es de 1GB de tamaño, y tu servidor tiene 10GB de RAM. Claramente tú puedes mantener todas las páginas de la base de datos en memoria, así que el intercambio de páginas nunca ocurre.
¿Qué ocurrirá si tú permitieras a la base de datos ejecutarse, con escrituras, cambios, inserciones, durante largo tiempo? Teóricamente todo estaría ok - todos los cambios serían registrados a WAL, y las páginas de memoria serían modificadas, todo bien. Ahora imagina, que después de 24 horas, el sistema es detenido - de nuevo - fallo de energía.
En el siguiente arranque Postgresql tendrá que leer, y aplicar, todos los cambios desde los segmentos WAL que ocurrieron en las últimas 24 horas. Eso es un montón de trabajo, y esto provocaría al arranque de Postgres tomar muuuuuuuucho tiempo.
Para resolver este problema, nosotros tenemos los checkpoints. Estos ocurren habitualmente automáticamente, pero tú puedes forzarlos para ocurrir a voluntad, lanzando el comando CHECKPOINT.
Así, ¿qué es el checkpoint? Checkpoint hace una cosa muy simple: escribe todas las páginas sucias desde la memoria al disco, las marca como "limpias" ("clean") en shared_buffers, y almacena la información que todos los wal que ahora están aplicados. Esto ocurre sin ningún bloqueo por supuesto. Así, la información inmediata desde aquí, es que la cantidad de trabajo que el nuevamente arrancado Postgresql tiene que hacer es relativa a cuánto tiempo pasó antes del último CHECKPONT y el momento en el que Postgresql se paró.
Esto nos trae de vuelva a - cuándo ocurre. Los checkpoints manuales no son comunes, habitualmente uno no piensa sobre ello - ocurre en segundo plano. ¿Cómo sabe Postgresql cuándo hacer checkpoint, entonces? Simple, gracias a dos parámetros de configuración:
checkpoint_segments
checkpoint_timeout
Y aquí, nosotros tenemos que aprender un poco sobre segmentos.
Tal y como yo escribí antes - WAL es (en teoría) un fichero infinito, que obtiene sólo nuevos datos (añadidos), y nunca sobreescribe.
Mientras esto es bonito en la teoría, la práctica es un poco más compleja. Por ejemplo - no hay de verdad ningún uso para los datos de WAL que fueron registrados antes del último checkpoint. Y los ficheros de tamaño infinito son (al menos por ahora) no posibles.
Los desarrolladores de Postgresql decidieron segmentar este WAL infinito en segmentos. Cada segmento tiene su número consecutivo, y es de 16MB en tamaño. Cuando un segmento se llena, Postgresql simplemente conmuta al siguiente.
Ahora, que nosotros sabemos qué son los segments nosotros podemos comprender qué hay acerca de checkpoint_segments. Es un número (por defecto: 3) que significa: si ese cantidad de segmentos fue llenada desde el último checkpoint, emite un nuevo checkpoint.
Con los valores por defecto, esto significa que si tú insertas datos que toman (en formato Postgresql) 6144 páginas (16MB de segmento es 2048 páginas, así que 3 segmentos son 6144 páginas) - automáticamente emitiría un checkpoint.
Segundo parámetro - checkpoint_timeout, es un intervalo de tiempo (por defecto a 5 minutos), y si este tiempo pasa desde el último checkpoint - un nuevo checkpoint será emitido. Tiene que entenderse que (generalmente) cuanto más a menudo hagas los checkpoint, menos invasivos son.
Esto viene de un hecho simple - generalmente, con el paso del tiempo, más y más páginas diferentes están sucias. Si hicieras checkpoint cada minuto - sólo las páginas del minuto tendrían que ser escritas a disco. 5 minutos - más páginas. 1 hora - incluso más páginas.
Mientras que hacer checkpoint no bloquea nada, tiene que entenderse que el checkpoint de (por ejemplo) 30 segmentos, causará escritura de alta intensidad de 480 MB de datos a disco. Y esto puede causar algunos relantizaciones para lecturas concurrentes.
Hasta aquí, yo espero, esto es muy claro.
Ahora, la siguiente parte del rompecabezas - segmentos de wal.
Estos ficheros (segmentos de wal) residen en el directorio pg_xlog/ del PGDATA de Postgresql:
=$ ls -l data/pg_xlog/
total 131076
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:39 000000010000000800000058
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:03 000000010000000800000059
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:03 00000001000000080000005A
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:04 00000001000000080000005B
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:04 00000001000000080000005C
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:04 00000001000000080000005D
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:06 00000001000000080000005E
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:06 00000001000000080000005F
drwx------ 2 pgdba pgdba 4096 2011-07-14 01:14 archive_status/
Cada nombre segmento contiene 3 bloques de 8 digitos en hexadecimal. Por ejemplo: 00000001000000080000005C significa:
00000001 – línea de tiempo 1
00000008 – 8º bloque
0000005C – segmento hexadecimal (5C) dentro del bloque
La última parte va sólo desde 00000000 a 000000FE (no FF!).
La 2ª parte del fichero más los 2 caracteres al final de la 3ª parte nos da la localización en este teórico fichero WAL infinito.
Dentro de Postresql nosotros podemos siempre comprobar cuál es la localización WAL actual:
$ select pg_current_xlog_location();
pg_current_xlog_location
--------------------------
8/584A62E0
(1 row)
Esto significa que nosotros estamos usando ahora el fichero xxxxxxxx000000080000058, y Postgresql está escribiendo en el desplazamiento 4A62E0 en él - el cual es 4874976, el cual, como el segmento de WAL es 16MB significa que el segmento de wal está lleno en ~ 25% ahora.
La cosa más misteriosa es la línea de tiempo. La línea de tiempo arranca desde 1, y se incrementa (por uno) cada vez que tú haces WAL-esclavo (WAL-slave) desde el servidor, y este esclavo es promocionado a autónomo (standalone).
Todo esta información nosotros podemos también conseguirla usando el programa pg_controldata:
=$ pg_controldata data
pg_control version number: 903
Catalog version number: 201107031
Database system identifier: 5628532665370989219
Database cluster state: in production
pg_control last modified: Thu 14 Jul 2011 01:49:12 AM CEST
Latest checkpoint location: 8/584A6318
Prior checkpoint location: 8/584A6288
Latest checkpoint's REDO location: 8/584A62E0
Latest checkpoint's TimeLineID: 1
Latest checkpoint's NextXID: 0/33611
Latest checkpoint's NextOID: 28047
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 727
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 33611
Time of latest checkpoint: Thu 14 Jul 2011 01:49:12 AM CEST
Minimum recovery ending location: 0/0
Backup start location: 0/0
Current wal_level setting: hot_standby
Current max_connections setting: 100
Current max_prepared_xacts setting: 0
Current max_locks_per_xact setting: 64
Maximum data alignment: 8
Database block size: 8192
Blocks per segment of large relation: 131072
WAL block size: 8192
Bytes per WAL segment: 16777216
Maximum length of identifiers: 64
Maximum columns in an index: 32
Maximum size of a TOAST chunk: 1996
Date/time type storage: 64-bit integers
Float4 argument passing: by value
Float8 argument passing: by value
Esto tiene alguna información interesante - por ejemplo la localización (en el fichero infinito de WAL) del último checkpoint, previo checkpoint, y localización REDO.
La localización REDO es muy importante - este es el lugar en el WAL desde el que Postgresql tendrá que leer si es matado, y rearrancado.
Los valores de encima no varían mucho porque este es mi sistema de pruebas el cual no tiene ningún tráfico ahora, pero nosotros podemos verlo en otra máquina:
=> pg_controldata data/
...
Latest checkpoint location: 623C/E07AC698
Prior checkpoint location: 623C/DDD73588
Latest checkpoint's REDO location: 623C/DE0915B0
...
La última cosa que es importante es para comprender qué ocurre con los segmentos de WAL obsoletos, y cómo "nuevos" segmentos de wal son creados.
Permíteme mostrarte una cosa de nuevo:
=$ ls -l data/pg_xlog/
total 131076
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:39 000000010000000800000058
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:03 000000010000000800000059
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:03 00000001000000080000005A
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:04 00000001000000080000005B
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:04 00000001000000080000005C
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:04 00000001000000080000005D
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:06 00000001000000080000005E
-rw------- 1 pgdba pgdba 16777216 2011-07-14 01:06 00000001000000080000005F
drwx------ 2 pgdba pgdba 4096 2011-07-14 01:14 archive_status/
Esto estaba en el sistema sin escrituras, y localización REDO 8/584A62E0.
Ya que el arranque de Postgresql necesitará leer desde esta localización, todos los segmentos de WAL anteriores a 000000010000000800000058 (por ejemplo 000000010000000800000057, 000000010000000800000056 y así) están obsoletos.
En el otro lado - por favor observa que nosotros tenemos listos 7 ficheros para uso futuro.
Postgresql trabaja de esta forma: si los segmentos WAL se quedan obsoletos (por ejemplo la localización REDO es posterior en WAL que este segmento) el fichero es renombrado. Esto es correcto. No es eliminado, es renombrado. ¿Renombrado a qué? Al siguiente fichero en WAL. Así cuando yo haga algunas esctiruas, y después haya checkpoint en la localización 8/59*, el fichero 000000010000000800000058 será renombrado a 000000010000000800000060.
Este es una de las razones por las que tus checkpoint_segments no deben ser demasiado bajos.
Pensemos por un momento sobre qué ocurriría si nosotros tuviéramos un checkpoint_timeout muy largo, y nosotros llenáramos todos los checkpoint_segments. Para grabar una nueva escritura Postgresql tendría que o hacer un checkpoint (lo cual hará), pero al mismo tiempo - no tendría más sementos listos dejados para uso. Así tendría que crear un nuevo fichero. Nuevo fichero, 16MB de datos (\x00 probablemente) - tendría que ser escrito a disco antes de que Postgresql pudiera escribir cualquier cosa que el usuario solicitara. Lo cual significa que si tú nunca alcanzaras checkpoint_segments la actividad de usuario concurrente se ralentizaría, porque postgresql tendrá que crear nuevos ficheros para alojar nuevas escrituras de datos solicitadas por los usuarios.
Habitualmente no es un problema, tú sólo configura checkpoint_segments a un número relativamente alto, y estás listo.
De todas formas. Cuando mirando en el directorio pg_xlog, los segmentos de WAL actuales (el que consigue las escrituras) está habitualmente en algún lugar en el medio. Lo cual pueda causar alguna confusión, porque el mtime (N. del T.: fecha y hora de modificación) de los ficheros no cambiarán en la misma dirección como los números de los ficheros. Como aquí:
$ ls -l
total 704512
-rw------- 1 postgres postgres 16777216 Jul 13 16:51 000000010000002B0000002A
-rw------- 1 postgres postgres 16777216 Jul 13 16:55 000000010000002B0000002B
-rw------- 1 postgres postgres 16777216 Jul 13 16:55 000000010000002B0000002C
-rw------- 1 postgres postgres 16777216 Jul 13 16:55 000000010000002B0000002D
-rw------- 1 postgres postgres 16777216 Jul 13 16:55 000000010000002B0000002E
-rw------- 1 postgres postgres 16777216 Jul 13 16:55 000000010000002B0000002F
-rw------- 1 postgres postgres 16777216 Jul 13 16:55 000000010000002B00000030
-rw------- 1 postgres postgres 16777216 Jul 13 17:01 000000010000002B00000031
-rw------- 1 postgres postgres 16777216 Jul 13 17:16 000000010000002B00000032
-rw------- 1 postgres postgres 16777216 Jul 13 17:21 000000010000002B00000033
-rw------- 1 postgres postgres 16777216 Jul 13 14:31 000000010000002B00000034
-rw------- 1 postgres postgres 16777216 Jul 13 14:32 000000010000002B00000035
-rw------- 1 postgres postgres 16777216 Jul 13 14:19 000000010000002B00000036
-rw------- 1 postgres postgres 16777216 Jul 13 14:36 000000010000002B00000037
-rw------- 1 postgres postgres 16777216 Jul 13 14:37 000000010000002B00000038
-rw------- 1 postgres postgres 16777216 Jul 13 14:38 000000010000002B00000039
-rw------- 1 postgres postgres 16777216 Jul 13 14:39 000000010000002B0000003A
-rw------- 1 postgres postgres 16777216 Jul 13 14:40 000000010000002B0000003B
-rw------- 1 postgres postgres 16777216 Jul 13 14:41 000000010000002B0000003C
-rw------- 1 postgres postgres 16777216 Jul 13 14:41 000000010000002B0000003D
-rw------- 1 postgres postgres 16777216 Jul 13 14:42 000000010000002B0000003E
-rw------- 1 postgres postgres 16777216 Jul 13 14:43 000000010000002B0000003F
-rw------- 1 postgres postgres 16777216 Jul 13 14:33 000000010000002B00000040
-rw------- 1 postgres postgres 16777216 Jul 13 14:34 000000010000002B00000041
-rw------- 1 postgres postgres 16777216 Jul 13 14:45 000000010000002B00000042
-rw------- 1 postgres postgres 16777216 Jul 13 14:55 000000010000002B00000043
-rw------- 1 postgres postgres 16777216 Jul 13 14:55 000000010000002B00000044
-rw------- 1 postgres postgres 16777216 Jul 13 14:55 000000010000002B00000045
-rw------- 1 postgres postgres 16777216 Jul 13 14:55 000000010000002B00000046
-rw------- 1 postgres postgres 16777216 Jul 13 14:55 000000010000002B00000047
-rw------- 1 postgres postgres 16777216 Jul 13 14:55 000000010000002B00000048
-rw------- 1 postgres postgres 16777216 Jul 13 15:09 000000010000002B00000049
-rw------- 1 postgres postgres 16777216 Jul 13 15:25 000000010000002B0000004A
-rw------- 1 postgres postgres 16777216 Jul 13 15:35 000000010000002B0000004B
-rw------- 1 postgres postgres 16777216 Jul 13 15:51 000000010000002B0000004C
-rw------- 1 postgres postgres 16777216 Jul 13 15:55 000000010000002B0000004D
-rw------- 1 postgres postgres 16777216 Jul 13 15:55 000000010000002B0000004E
-rw------- 1 postgres postgres 16777216 Jul 13 15:55 000000010000002B0000004F
-rw------- 1 postgres postgres 16777216 Jul 13 15:55 000000010000002B00000050
-rw------- 1 postgres postgres 16777216 Jul 13 15:55 000000010000002B00000051
-rw------- 1 postgres postgres 16777216 Jul 13 15:55 000000010000002B00000052
-rw------- 1 postgres postgres 16777216 Jul 13 16:19 000000010000002B00000053
-rw------- 1 postgres postgres 16777216 Jul 13 16:35 000000010000002B00000054
drwx------ 2 postgres postgres 96 Jun 4 23:28 archive_status
Por favor observa que el fichero más nuevo - 000000010000002B00000033 no es ni el primero, ni el último. Y el fichero más viejo - está cerca despúes del más nuevo - 000000010000002B00000036.
Esto es todo natural. Todos los ficheros antes del actual, son los que aún son necesitados, y sus mtimes irán en la misma dirección como la numeración de los segmentos de WAL.
El último fichero (basado en nombre de ficheros) - *54 tiene un mtime justo antes de *2A - lo cual nos dice que fue previamente *29, pero que fue renombrado cuando la localización REDO movió a algún lugar al fichero *2A.
Espero que esté claro desde explicación de arriba, si no - por favor expresa tus preguntas/asuntos en los comentarios.
Así, para envolverlo. WAL existe para guardar tu tocino en caso de emergencia. Gracias a WAL es muy difícil conseguir ningún problema con los datos - yo incluso diría que imposible, pero es aún posible en caso de mal comportamiento de hardware - como: mentiras sobre las escrituras de disco actuales.
WAL es almacenado en un número de ficheros en el directorio pg_xlog/, y los ficheros son reutilizados, así el directorio no debe de crecer. El número de estos ficheros es habitualmente 2 * checkpoint_segments + 1.
¿Espera? ¿Por qué 2 * checkpoint_segments?
La razón es muy simple. Asumamos que tú tienes checkpoint_segments configurado a 5. Tú los llenaste todos, y el checkpoint es llamado. Checkpoint es llamado en el segmento WAL #x. En #x + 5 nosotros tendremos otro checkpoint. Pero Postgresql siempre mantiene (al menos) checkpoint_segments por delante de la actual localización, para evitar necesitar crear nuevos segmentos para datos desde las consultas de los usuarios. Así, en cualquier momento dado, tú podrías tener:
segmento actual
segmentos checkpoint_segments, desde la localización REDO
"buffer" de checkpoint_segments en frente de la localización actual
Algunas veces, cuando tú tienes más escrituras checkpoint_segments, in tal caso Postgresql creará nuevos segmentos (como yo describí arriba). Lo cual inflará el número de ficheros en el directorio pg_xlog/. Pero esto será restaurado después de algún tiempo - simplemente algunos segmentos obsoletos no será renombrados, aunque en cambio serán eliminados.
Finalmente, la última cosa. GUC (N. del T.: GUC es es el acrónimo de Grand Unified Configuration Setting, es decir, las configuraciones de postgresl, como las que se ponen en postgresql.conf) "checkpoint_warning". Esto es también (como checkpoint_timeout) un intervalor, habitualmente mucho más corto - por defecto 30 segundos. Esto es usado para registrar (no a WAL, sino al registro normal) información si los checkpoint automáticos ocurren demasiado a menudo.
Como checkpoint_timeout es supuestamente más grande que el checkpoint_warning, esto normalmente significa que alerta si tú llenaste más cantidad de checkpoint_segments de registro en el tiempo del checkpoint_timeout.
Tal información se parece a esta:
2011-07-14 01:03:22.160 CEST @ 7370 LOG: checkpoint starting: xlog
2011-07-14 01:03:26.175 CEST @ 7370 LOG: checkpoint complete: wrote 1666 buffers (40.7%); 0 transaction log file(s) added, 0 removed, 3 recycled; write=3.225 s, sync=0.720 s, total=4.014 s; sync files=5, longest=0.292 s, average=0.144 s
2011-07-14 01:03:34.904 CEST @ 7370 LOG: checkpoints are occurring too frequently (12 seconds apart)
2011-07-14 01:03:34.904 CEST @ 7370 HINT: Consider increasing the configuration parameter "checkpoint_segments".
2011-07-14 01:03:34.904 CEST @ 7370 LOG: checkpoint starting: xlog
2011-07-14 01:03:39.239 CEST @ 7370 LOG: checkpoint complete: wrote 1686 buffers (41.2%); 0 transaction log file(s) added, 0 removed, 3 recycled; write=3.425 s, sync=0.839 s, total=4.334 s; sync files=5, longest=0.267 s, average=0.167 s
2011-07-14 01:03:48.077 CEST @ 7370 LOG: checkpoints are occurring too frequently (14 seconds apart)
2011-07-14 01:03:48.077 CEST @ 7370 HINT: Consider increasing the configuration parameter "checkpoint_segments".
2011-07-14 01:03:48.077 CEST @ 7370 LOG: checkpoint starting: xlog
Por favor, observa las líneas "HINT".
Esas son sólo consejos (no es un aviso, o fatalidades) porque checkpoint_segments demasiado bajo no causa ningún riesgo a tus datos - eso solo puede ralentizar la interacción con los clientes, si el usuario enviara consultas de modificación, que tendrán que esperar para que nuevos segmentos de WAL sean creados (por ejemplo 16MB escritos a disco).
Como última nota - si tú estás teniendo alguna clase de monitorización de su Postgresql (como cati, o ganglia, o munin o alguno comercial, como circonus) tú podrías querer añadir gráficos que te mostraran tu progreso WAL en el tiempo.
Para hacerlo, tú necesitarías convertir la localización xlog actual a algún número decimal normal, y después dibujar las diferencias. Por ejemplo como esto:
=$ psql -qAtX -c "select pg_current_xlog_location()" | \
awk -F/ 'BEGIN{print "ibase=16"} {printf "%s%08s\n", $1, $2}' | \
bc
108018127223360
O, si los números son demasiado grandes, sólo el "número" decimal del fichero:
=$ (
echo "ibase=16"
psql -qAtX -c "select pg_xlogfile_name(pg_current_xlog_location())" | \
cut -b 9-16,23-24
) | bc
6438394
Dibujar incrementos del 2º valor (6438394) en incrementos de 5 minutos te dirá cuál es el checkpoint_segments óptimo (aunque siempre recuerda hacerlo un poco más grande que el realmente necesitado, por si acaso un pico repentino de tráfico).
domingo, 21 de agosto de 2016
viernes, 19 de agosto de 2016
Comprender postgresql.conf: checkpoint_completion_target - UNDERSTANDING POSTGRESQL.CONF : CHECKPOINT_COMPLETION_TARGET
Esta entrada es una traducción de https://www.depesz.com/2010/11/03/checkpoint_completion_target/
La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2010/11/03/checkpoint_completion_target/
The translation may contain errors.
Arrancando nuevas series del blog - explicación de varios parámetros de configuración.
Yo no seguiré por supuesto una programación u orden - si yo hubiera tenido que hacerlo - sería mi trabajo, y de esta manera - es divertido.
El primer parámetro de configuración sobre el que es escribir es checkpoint_completion_target.
Primero, vamos a pensar acerca de qué es el checkpoint.
Como tú tal vez sabes Postgresql mantiene cache de páginas (bloques de disco de 8kB (por defecto)) en RAM. Para hacerlo disponible a todos los backends (N. de T.: procesos en segundos plano), es almacenado en shared_buffers, y está (normalmente) tomando la mayoría de shared_buffers.
Si Pg necesita hacer algo con una página dada, comprueba si está en shared_buffers, y si no - la carga (haciendo alguna lógica para asegurar que no excederá el tamaño de shared_buffers añadiendo la nueva página).
Esto también ocurre en las escrituras.
Cuando tú escribes algo (piensa: insert, update, delete) el cambio no es escrito a la tabla. En cambio es escrito a estas páginas en memoria.
Ahora por supuesto hay una pregunta - ¿qué ocurre si hubiera una caída del servidor? ¿Como los datos están en ram yo lo perderé? No. Porque los datos están también escritos a "WAL". WAL son aquellos ficheros de 16MB en el directorio pg_xlog. Estos son (virtualmente) nunca leídos, y sólo contienen la lista de cambios a páginas.
Así, el flujo se parece como esto: tú haces un insert. Postgresql carga la página a memoria (si ella no estuvo allí anteriormente), la modifica, y escribe la información sobre la modificación al WAL. El cambio no es aplicado a los ficheros de la tabla real.
Ahora - después de algún tiempo - hay un montón de páginas modificadas en memoria, que no están aplicadas a la tabla. Y esto es cuando CHECKPOINT ocurre. Hay alguna lógica cuando el checkpoint es emitido (yo escribiré sobre ello en algún post del blog más adelante), pero por ahora, la parte importante es: cuando el checkpoint ocurre, todas las páginas modificadas (también llamadas sucias (N. del T.: dirty en inglés)) son escritas a la actual tabla y a los ficheros de índices.
¿Hasta aquí todo bien? Eso espero.
Ahora - el tamaño del checkpoint es por supuesto variable, pero depende del tamaño de shared_buffers, y cómo de a menudo tú tengas checkpoints, y cómo de intensiva en escritura es tu aplicación.
Imaginemos, que tú tienes un servidor con 100GB de shared_buffers (es un montón, pero no inaudito). Y es intensivo en escritura. Así, cuando el checkpoint ocurre, podría necesitar volcar 100GB de datos a disco. Más o menos a la vez. Es un problema. Porque es un gran pico de I/O (N. del T.: I/O es input/output, E/S entrada/salida), e influirá directamente en el rendimiento de concurrencia de las consultas normales.
Esto es donde checkpoint_completion_target aparece.
Generalmente es un parámetro que hace que Postgresql intente escribir los datos más lento - para finalizar en el tiempo checkpoint_completion_target * checkpoint_timeout. Normalmente tú tienes checkpoint_timeout configurado a 5 minutos (a menos que tú lo modificaras), y el checkpoint_completion_target por defecto es 0.5. Esto significa que Postgresql intentará hacer que el checkpoint tome 2.5 minutos - para hacer la carga de I/O más lenta.
Vamos de vuelta a nuestro ejemplo. Nosotros tenemos 100GB de datos para ser escritos a ficheros. Y mi disco puede mantener 1GB por segundo de escrituras (es un gran servidor con un gran I/O). Cuando haciendo el checkpoint normal (la forma que había antes de 8.3), esto tomaría 100 segundos al 100% de utilización del ancho de banda para escribir los datos.
Pero - con checkpoint_completion_target configurado a 0.5 - Postgresql intentará escribir los datos en 2.5 minutos - así efectivamente usando sólo ~ 700 MB/s, y dejando 30% de capacidad de I/O para otras tareas. Es una gran beneficio.
El problema con este enfoque es relativamente simple - como el checkpoint toma mucho tiempo para escribir, los segmentos wal obsoletos, viejos, permanecen más tiempo en el directorio pg_xlog, que crecerá más.
En la época de 8.2, el número de ficheros en el directorio pg_xlog iba habitualmente hasta 2 * checkpoint_segments + 1.
Ahora, puede ser estimado para ser ( 2 + checkpoint_completion_target ) * checkpoint_segments + 1.
Si tú leiste los párrafos de arriba con atención al detalle tú viste que yo usé la palabrá "intentar". La razón es muy simple - el ancho de banda afectivo de I/O es variable, así que no hay garantía. Así, vemos cómo realmente trabaja.
Para las pruebas, yo uso mi máquina de pruebas, con una configuración que coloca datos, xlogs y logs de consultas (útil para pruebas para bloqueos/ralentizaciones) en particiones separadas.
Mientras poner estos en particiones separadas de el mismo disco no incrementará el rendimiento, me permitirá monitorizar exactamente qué ocurre en cada una de las particiones mientras las pruebas.
Con estas 3 particiones, yo las dispondré así:
sda1 - swap, no debe de ser usado, así que no es importante.
sda2 - filesystem raiz (N. del T.: root), y lugar donde los logs de las consultas y de iostat están almacenados
sda3 - $PGDATA
sda4 - pg_xlog - segmentos wal
Para probar Pg, yo estoy usando el programa pgbench estándar, con escala de 35 (-s 35 que significa que la base de datos generada, sin ningún test hecho, es ~ 550MB).
Yo podría haber usado una base de datos más grande, pero como pgbench escribe por toda la base de datos, yo quiero asegurarme que las escrituras a las tablas ocurren sólo debido a los checkpoint, y no porque algún shared_buffer tiene que ser liberado para hacer lugar a otro.
Dado que my HDD mantiene ~ 50MB/s de escrituras, yo puedo asumir que el checkpoint con checkpoint_completion_target = 0 debe de tomar ~ 11 segundos.
Configuración usada:
shared_buffers = 1024MB - Yo necesito grandes shared buffers para ser capaz de observa los tiempos de checkpoint.
log_checkpoints = on – bien, yo necesito saber cuándo los checkpoit ocurren
checkpoint_segments = 30 - sólo un número de cuántos segmentos WAL pueden ser llenados antes de que checkpoint sea forzado
checkpoint_timeout = 5min - cada cuanto tiempo hacer checkpoint de los datos
checkpoint_warning = 5min - si el checkpoint ocurre más a menudo que esto (lo cual es lo mismo que el timeout) - avisar sobre ello en los logs. Esto es para ver la situación cuando nosotros tenemos demasiados pocos checkpoint_segments.
log_line_prefix = ‘%m %r %u %d %p ‘ – para tener los logs de consultas de pg bien prefijados con la información importante
log_min_duration_statement = 5 - yo no quiero dejar registro de todas las consultas - ya que habrá muchas. Yo sólo quiero registrar aquellas que sobrepasen los 5ms - así yo veré si habrá picos en el número de esas consultas en los checkpoints.
Yo hice 5 pruebas, con checkpoint_completion_target siendo: 0, 0.3, 0.6, 0.9 y 1.
Esta es la utilización de IO de la partición PGDATA con checkpoint_completion_target = 0:

¿Qué es el %util? Desde el comando man iostat:
Porcentaje de tiempo de CPU durante el que las peticiones de I/O fueron enviadas al dispositivo (utilización del ancho de banda del dispositivo). La saturación del dispositivo ocurre cuando este valor es cercano al 100%.
Y, basado en el gráfico de arriba, yo inmediatamente vi que mi conjunto de datos de pruebas es demasiado grande, ya que el checkpoint tomó la mayoría del tiempo.
Así, yo rehice la prueba, con un conjunto de datos incluso más pequeño - escala 15, tamaño de la base de datos - ~ 300MB).
Resultados
checkpoint_completion_target = 0
Pgbench estuvo poniendo la carga en la base de datos entre 14:57:34 y 15:09:34. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada
Esta es la utlilización de IO de la partición de PGDATA:

¿Qué es el %util? Desde el comando man iostat:
Porcentaje de tiempo de CPU durante el que las peticiones de I/O fueron enviadas al dispositivo (utilización del ancho de banda del dispositivo). La saturación del dispositivo ocurre cuando este valor es cercano al 100%.
Rendimiento de escritura:

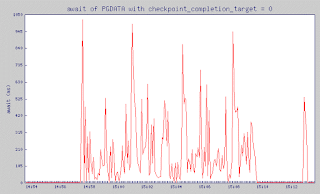
y finalmente, un valor muy importante - await
El tiempo medio (en milisegundos) para peticiones I/O enviadas al dispositivo para ser servidas. Esto incluye el tiempo gastado por las peticiones en la cola y el tiempo gastado sirviéndolas.
checkpoint_completion_target = 0.3
Pgbench estuvo poniendo la carga en la base de datos entre 15:29:44 y 15:41:44. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



checkpoint_completion_target = 0.6
Pgbench estuvo poniendo la carga en la base de datos entre 16:01:55 y 16:13:55. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



checkpoint_completion_target = 0.9
Pgbench estuvo poniendo la carga en la base de datos entre 16:34:08 y 16:46:08. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



checkpoint_completion_target = 1
Pgbench estuvo poniendo la carga en la base de datos entre 17:06:21 y 17:18:22. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



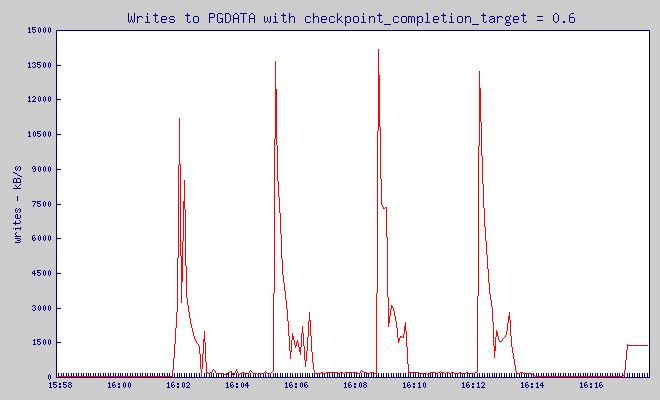
Estos gráficos son muy dentados, pero yo esper que tú puedas ver que mientras checkpoint_completion_target escribió en un gran pico que uso 40MB de tráfico de escritura, con todos los otros valores de checkpoint_completion_target el pico de escritura fue mucho más pequeño.
¿Y cómo se está relacionando al número de consultas lentas? Como tú tal vez recuerdes - yo registré cada consulta que tomó más de 5ms. Basado en el registro de consultas, yo puede ver cómo de frecuente nosotros tuvimos consultas lentas.
Como tú puedes ver incrementar checkpoint_completion_target ofrece un visible decremento en el número de consultas que tomaron más de 200ms. El rango (100,200) ms es diferente, pero podemos ver que las consultas más largas, y más perturbadoras, son mucho menos comunes que sucedan con un mayor checkpoint_completion_target.
Así, ¿hay algún inconveniente para incrementarlo?
Bien, para los que empiezan - puede inflar el directorio pg_xlog, de acuerdo a la fórmula que yo traje al comienzo del post.
Y segundo - no siempre funciona - si tus shared_buffers son demasiado grandes, y tú escribe a ellos demasiado - pg tendrá que hacer checkpoint virtualmente todo el tiempo - tal y como ocurrió en el primer gráfico que yo mostré, así cualquier "ralentización" simplemente no funcionará.
Finalmente - recuerda que el será más largo el tiempo desde el último checkpoint en caso de apagado forzado (piensa: corte de energía) - más largo tiempo llevará la recuperación. Y como un checkpoint_completion_target más largo significa checkpoint más lentos - esto también te hace (de media) ir más lejos del último checkpoint - así haciendo la eventual recuperación más larga.
Dejando de lado estos hecho - yo no puedo realmente pensar niguna razón para no hacerlo a 0.9 (yo no iría con 1.0, para evitar la situación cuando el siguiente checkpoint es pospuesto, debido a que el previo no ha sido hecho aún) como un cambio básico en el ajuste de Postgresql.
La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2010/11/03/checkpoint_completion_target/
The translation may contain errors.
Arrancando nuevas series del blog - explicación de varios parámetros de configuración.
Yo no seguiré por supuesto una programación u orden - si yo hubiera tenido que hacerlo - sería mi trabajo, y de esta manera - es divertido.
El primer parámetro de configuración sobre el que es escribir es checkpoint_completion_target.
Primero, vamos a pensar acerca de qué es el checkpoint.
Como tú tal vez sabes Postgresql mantiene cache de páginas (bloques de disco de 8kB (por defecto)) en RAM. Para hacerlo disponible a todos los backends (N. de T.: procesos en segundos plano), es almacenado en shared_buffers, y está (normalmente) tomando la mayoría de shared_buffers.
Si Pg necesita hacer algo con una página dada, comprueba si está en shared_buffers, y si no - la carga (haciendo alguna lógica para asegurar que no excederá el tamaño de shared_buffers añadiendo la nueva página).
Esto también ocurre en las escrituras.
Cuando tú escribes algo (piensa: insert, update, delete) el cambio no es escrito a la tabla. En cambio es escrito a estas páginas en memoria.
Ahora por supuesto hay una pregunta - ¿qué ocurre si hubiera una caída del servidor? ¿Como los datos están en ram yo lo perderé? No. Porque los datos están también escritos a "WAL". WAL son aquellos ficheros de 16MB en el directorio pg_xlog. Estos son (virtualmente) nunca leídos, y sólo contienen la lista de cambios a páginas.
Así, el flujo se parece como esto: tú haces un insert. Postgresql carga la página a memoria (si ella no estuvo allí anteriormente), la modifica, y escribe la información sobre la modificación al WAL. El cambio no es aplicado a los ficheros de la tabla real.
Ahora - después de algún tiempo - hay un montón de páginas modificadas en memoria, que no están aplicadas a la tabla. Y esto es cuando CHECKPOINT ocurre. Hay alguna lógica cuando el checkpoint es emitido (yo escribiré sobre ello en algún post del blog más adelante), pero por ahora, la parte importante es: cuando el checkpoint ocurre, todas las páginas modificadas (también llamadas sucias (N. del T.: dirty en inglés)) son escritas a la actual tabla y a los ficheros de índices.
¿Hasta aquí todo bien? Eso espero.
Ahora - el tamaño del checkpoint es por supuesto variable, pero depende del tamaño de shared_buffers, y cómo de a menudo tú tengas checkpoints, y cómo de intensiva en escritura es tu aplicación.
Imaginemos, que tú tienes un servidor con 100GB de shared_buffers (es un montón, pero no inaudito). Y es intensivo en escritura. Así, cuando el checkpoint ocurre, podría necesitar volcar 100GB de datos a disco. Más o menos a la vez. Es un problema. Porque es un gran pico de I/O (N. del T.: I/O es input/output, E/S entrada/salida), e influirá directamente en el rendimiento de concurrencia de las consultas normales.
Esto es donde checkpoint_completion_target aparece.
Generalmente es un parámetro que hace que Postgresql intente escribir los datos más lento - para finalizar en el tiempo checkpoint_completion_target * checkpoint_timeout. Normalmente tú tienes checkpoint_timeout configurado a 5 minutos (a menos que tú lo modificaras), y el checkpoint_completion_target por defecto es 0.5. Esto significa que Postgresql intentará hacer que el checkpoint tome 2.5 minutos - para hacer la carga de I/O más lenta.
Vamos de vuelta a nuestro ejemplo. Nosotros tenemos 100GB de datos para ser escritos a ficheros. Y mi disco puede mantener 1GB por segundo de escrituras (es un gran servidor con un gran I/O). Cuando haciendo el checkpoint normal (la forma que había antes de 8.3), esto tomaría 100 segundos al 100% de utilización del ancho de banda para escribir los datos.
Pero - con checkpoint_completion_target configurado a 0.5 - Postgresql intentará escribir los datos en 2.5 minutos - así efectivamente usando sólo ~ 700 MB/s, y dejando 30% de capacidad de I/O para otras tareas. Es una gran beneficio.
El problema con este enfoque es relativamente simple - como el checkpoint toma mucho tiempo para escribir, los segmentos wal obsoletos, viejos, permanecen más tiempo en el directorio pg_xlog, que crecerá más.
En la época de 8.2, el número de ficheros en el directorio pg_xlog iba habitualmente hasta 2 * checkpoint_segments + 1.
Ahora, puede ser estimado para ser ( 2 + checkpoint_completion_target ) * checkpoint_segments + 1.
Si tú leiste los párrafos de arriba con atención al detalle tú viste que yo usé la palabrá "intentar". La razón es muy simple - el ancho de banda afectivo de I/O es variable, así que no hay garantía. Así, vemos cómo realmente trabaja.
Para las pruebas, yo uso mi máquina de pruebas, con una configuración que coloca datos, xlogs y logs de consultas (útil para pruebas para bloqueos/ralentizaciones) en particiones separadas.
Mientras poner estos en particiones separadas de el mismo disco no incrementará el rendimiento, me permitirá monitorizar exactamente qué ocurre en cada una de las particiones mientras las pruebas.
Con estas 3 particiones, yo las dispondré así:
sda1 - swap, no debe de ser usado, así que no es importante.
sda2 - filesystem raiz (N. del T.: root), y lugar donde los logs de las consultas y de iostat están almacenados
sda3 - $PGDATA
sda4 - pg_xlog - segmentos wal
Para probar Pg, yo estoy usando el programa pgbench estándar, con escala de 35 (-s 35 que significa que la base de datos generada, sin ningún test hecho, es ~ 550MB).
Yo podría haber usado una base de datos más grande, pero como pgbench escribe por toda la base de datos, yo quiero asegurarme que las escrituras a las tablas ocurren sólo debido a los checkpoint, y no porque algún shared_buffer tiene que ser liberado para hacer lugar a otro.
Dado que my HDD mantiene ~ 50MB/s de escrituras, yo puedo asumir que el checkpoint con checkpoint_completion_target = 0 debe de tomar ~ 11 segundos.
Configuración usada:
shared_buffers = 1024MB - Yo necesito grandes shared buffers para ser capaz de observa los tiempos de checkpoint.
log_checkpoints = on – bien, yo necesito saber cuándo los checkpoit ocurren
checkpoint_segments = 30 - sólo un número de cuántos segmentos WAL pueden ser llenados antes de que checkpoint sea forzado
checkpoint_timeout = 5min - cada cuanto tiempo hacer checkpoint de los datos
checkpoint_warning = 5min - si el checkpoint ocurre más a menudo que esto (lo cual es lo mismo que el timeout) - avisar sobre ello en los logs. Esto es para ver la situación cuando nosotros tenemos demasiados pocos checkpoint_segments.
log_line_prefix = ‘%m %r %u %d %p ‘ – para tener los logs de consultas de pg bien prefijados con la información importante
log_min_duration_statement = 5 - yo no quiero dejar registro de todas las consultas - ya que habrá muchas. Yo sólo quiero registrar aquellas que sobrepasen los 5ms - así yo veré si habrá picos en el número de esas consultas en los checkpoints.
Yo hice 5 pruebas, con checkpoint_completion_target siendo: 0, 0.3, 0.6, 0.9 y 1.
Esta es la utilización de IO de la partición PGDATA con checkpoint_completion_target = 0:

¿Qué es el %util? Desde el comando man iostat:
Porcentaje de tiempo de CPU durante el que las peticiones de I/O fueron enviadas al dispositivo (utilización del ancho de banda del dispositivo). La saturación del dispositivo ocurre cuando este valor es cercano al 100%.
Y, basado en el gráfico de arriba, yo inmediatamente vi que mi conjunto de datos de pruebas es demasiado grande, ya que el checkpoint tomó la mayoría del tiempo.
Así, yo rehice la prueba, con un conjunto de datos incluso más pequeño - escala 15, tamaño de la base de datos - ~ 300MB).
Resultados
checkpoint_completion_target = 0
Pgbench estuvo poniendo la carga en la base de datos entre 14:57:34 y 15:09:34. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada
Esta es la utlilización de IO de la partición de PGDATA:

¿Qué es el %util? Desde el comando man iostat:
Porcentaje de tiempo de CPU durante el que las peticiones de I/O fueron enviadas al dispositivo (utilización del ancho de banda del dispositivo). La saturación del dispositivo ocurre cuando este valor es cercano al 100%.
Rendimiento de escritura:

y finalmente, un valor muy importante - await
El tiempo medio (en milisegundos) para peticiones I/O enviadas al dispositivo para ser servidas. Esto incluye el tiempo gastado por las peticiones en la cola y el tiempo gastado sirviéndolas.

checkpoint_completion_target = 0.3
Pgbench estuvo poniendo la carga en la base de datos entre 15:29:44 y 15:41:44. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



checkpoint_completion_target = 0.6
Pgbench estuvo poniendo la carga en la base de datos entre 16:01:55 y 16:13:55. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada


checkpoint_completion_target = 0.9
Pgbench estuvo poniendo la carga en la base de datos entre 16:34:08 y 16:46:08. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada



checkpoint_completion_target = 1
Pgbench estuvo poniendo la carga en la base de datos entre 17:06:21 y 17:18:22. Antes de ello, durante 5 minutos - el servidor no estuvo haciendo nada

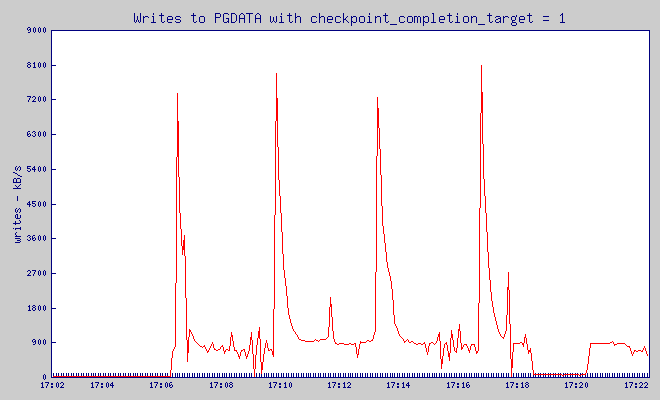

Estos gráficos son muy dentados, pero yo esper que tú puedas ver que mientras checkpoint_completion_target escribió en un gran pico que uso 40MB de tráfico de escritura, con todos los otros valores de checkpoint_completion_target el pico de escritura fue mucho más pequeño.
¿Y cómo se está relacionando al número de consultas lentas? Como tú tal vez recuerdes - yo registré cada consulta que tomó más de 5ms. Basado en el registro de consultas, yo puede ver cómo de frecuente nosotros tuvimos consultas lentas.
| cct | número de consultas ejecutándose más de | ||||
|---|---|---|---|---|---|
| 100ms | 200ms | 300ms | 400ms | 500ms | |
| 0 | 122 | 52 | 51 | 44 | 37 |
| 0.3 | 92 | 41 | 37 | 36 | 31 |
| 0.6 | 122 | 34 | 29 | 28 | 23 |
| 0.9 | 164 | 30 | 18 | 17 | 16 |
| 1 | 173 | 23 | 13 | 13 | 12 |
Como tú puedes ver incrementar checkpoint_completion_target ofrece un visible decremento en el número de consultas que tomaron más de 200ms. El rango (100,200) ms es diferente, pero podemos ver que las consultas más largas, y más perturbadoras, son mucho menos comunes que sucedan con un mayor checkpoint_completion_target.
Así, ¿hay algún inconveniente para incrementarlo?
Bien, para los que empiezan - puede inflar el directorio pg_xlog, de acuerdo a la fórmula que yo traje al comienzo del post.
Y segundo - no siempre funciona - si tus shared_buffers son demasiado grandes, y tú escribe a ellos demasiado - pg tendrá que hacer checkpoint virtualmente todo el tiempo - tal y como ocurrió en el primer gráfico que yo mostré, así cualquier "ralentización" simplemente no funcionará.
Finalmente - recuerda que el será más largo el tiempo desde el último checkpoint en caso de apagado forzado (piensa: corte de energía) - más largo tiempo llevará la recuperación. Y como un checkpoint_completion_target más largo significa checkpoint más lentos - esto también te hace (de media) ir más lejos del último checkpoint - así haciendo la eventual recuperación más larga.
Dejando de lado estos hecho - yo no puedo realmente pensar niguna razón para no hacerlo a 0.9 (yo no iría con 1.0, para evitar la situación cuando el siguiente checkpoint es pospuesto, debido a que el previo no ha sido hecho aún) como un cambio básico en el ajuste de Postgresql.
jueves, 18 de agosto de 2016
Registrar consultas - ¿Cómo? - LOGGING QUERIES – HOW?
Esta entrada es una traducción de https://www.depesz.com/2010/07/22/logging-queries-how/
La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2010/07/22/logging-queries-how/
The translation may contain errors.
Una de las preguntas que saltan frecuentemente en el IRC es cómo ver las consultas que se ejecutan ahora en el servidor, y qué consultas lo fueron antes.
Teóricamente la respuesta a esto es simple - pg_stat_activity y log_min_duration_statement. O log_statment. ¿Cuál es la diferencia? Esto es exactamente por qué estoy escribiendo este post.
Lo primero de todo - para ver qué está ocurriendo en la base de datos justo ahora - tú puedes usar:
$ select * from pg_stat_activity ;
-[ RECORD 1 ]----+---------------------------------
datid | 16398
datname | depesz
procpid | 28765
usesysid | 16387
usename | depesz
application_name | psql
client_addr | [null]
client_port | -1
backend_start | 2010-07-21 15:44:08.017051+02
xact_start | 2010-07-21 15:46:13.92332+02
query_start | 2010-07-21 15:46:13.92332+02
waiting | f
current_query | select * from pg_stat_activity ;
La descripción exacta de qué es qué, tú la puedes encontrar en el bonito manual.
Hay un par de cosas importante, aunque:
current_query recorta las consultas largas a algún tamaño (no recuerdo cómo de grandes están ok, y es seguro que más grandes que las consultas usadas habitualmente, pero el límite existe)
A veces el campo "current_query" puede contener la cadena " - esto ocurre cuando tú estás consultando pg_stat_activvity desde no superusuario, y algunas consultas son ejecutadas por un usuario diferente que el usuario con el que tú has iniciado sesión.
Aparte de estos pequeños casos, esta es perfectamente la forma buena para ver el estado actual del sistema. Especialmente cuando añadiendo where para filtrar conexiones desocupadas. Mi consulta favorita para esta vista es:
SELECT
now() - query_start as runtime,
case when waiting then 'WAIT' else '' end as wait,
current_query
FROM
pg_stat_activity
WHERE
current_query <> '<IDLE>'
ORDER BY 1 DESC
Esto muestra las consultas que están trabajando, no desocupadas, con su correspondiente tiempo de ejecución, ordenadas por el tiempo de ejecución mayor, con información si la consulta está esperando por algo.
Ahora, ¿qué hay sobre ver todas las consultas?
Bien, nosotros necesitamos usar una de las GUCS (N. del T.: GUCS es el acrónimo de Grand Unified Configuration Setting): log_statement o log_min_duration_statement.
Lo primero, veamos log_statement. Puede tener 4 valores: none, ddl, mod y all.
Estos significan:
none - ninguna sentencia será registrada (por los mecanismos de log_statement - pueden aún ser registradas por alguna otra cosa)
ddl - sentencias como create, alter y drop serán registradas - es decir, todo lo que cambia el esquema de la base de datos
mod - registra todas las consultas que "ddl" registraría, más las sentencias insert, update, delete, truncate y "copy from"
all – registra todas las consultas
Hay también algunas observaciones importantes:
si tú llamas a una función (select function()) y ella internamente hace algunas modificaciones - no será registrado con log_statement <> all
las consultas son registradas antes de que ellas sean realmente ejecutadas (lo cual es muy guay, aunque es importante observar la diferencia desde la forma descrita abajo)
Vamos a ver cómo se muestra (estos son registros csv, desplázate a la derecha para ver las partes importantes):
2010-07-21 21:54:16.135 CEST,"depesz","depesz",18160,"[local]",4c475062.46f0,3,"idle",2010-07-21 21:54:10 CEST,2/4,0,LOG,00000,"statement: create table x (i int4);",,,,,,,,,"psql"
2010-07-21 21:54:21.344 CEST,"depesz","depesz",18160,"[local]",4c475062.46f0,4,"idle",2010-07-21 21:54:10 CEST,2/5,0,LOG,00000,"statement: insert into x (i) values (123);",,,,,,,,,"psql"
2010-07-21 21:54:24.094 CEST,"depesz","depesz",18160,"[local]",4c475062.46f0,5,"idle",2010-07-21 21:54:10 CEST,2/6,0,LOG,00000,"statement: select * from x;",,,,,,,,,"psql"
Y finalmente, log_min_duration_statement. Esta es (en mi opinión) la más útil de todas ellas. Si yo la activo (es decir, establecida a valor >=0), y ejecuto las mismas consultas, en los registros yo puedo ver:
2010-07-21 22:03:27.690 CEST,"depesz","depesz",18723,"[local]",4c475288.4923,4,"CREATE TABLE",2010-07-21 22:03:20 CEST,2/0,0,LOG,00000,"duration: 45.924 ms statement: create table x (i int4);",,,,,,,,,"psql"
2010-07-21 22:03:31.236 CEST,"depesz","depesz",18723,"[local]",4c475288.4923,5,"INSERT",2010-07-21 22:03:20 CEST,2/0,0,LOG,00000,"duration: 12.251 ms statement: insert into x (i) values (123);",,,,,,,,,"psql"
2010-07-21 22:03:33.724 CEST,"depesz","depesz",18723,"[local]",4c475288.4923,6,"SELECT",2010-07-21 22:03:20 CEST,2/0,0,LOG,00000,"duration: 0.307 ms statement: select * from x;",,,,,,,,,"psql"
Añadido importante: duration: ... elementos, que muestran cuanto tiempo tomó la sentencia.
Esto significa que las sentencias (y las duraciones) registradas por log_min_duration_statement pueden ser registradas sólo después de la ejecución. En la otra cara, log_min_duration te da la capacidad para registrar consultas que tomaron más allá de un tiempo definido - por ejemplo 5ms, o 15 segundos, así que tú puedes ajustarlo para registrar lo que es demasiado largo para tu aplicación.
Una nota sin embargo. Si tú activaras ambos log_statment (a algún valor) y log_min_duration_statement, y alguna consulta coincidiera en ambos casos, tú verás:
2010-07-21 22:12:58.423 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,5,"idle",2010-07-21 22:12:54 CEST,2/3,0,LOG,00000,"statement: create table x (i int4);",,,,,,,,,"psql"
2010-07-21 22:12:58.437 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,6,"CREATE TABLE",2010-07-21 22:12:54 CEST,2/0,0,LOG,00000,"duration: 14.017 ms",,,,,,,,,"psql"
2010-07-21 22:13:00.253 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,7,"idle",2010-07-21 22:12:54 CEST,2/4,0,LOG,00000,"statement: insert into x (i) values (123);",,,,,,,,,"psql"
2010-07-21 22:13:00.255 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,8,"INSERT",2010-07-21 22:12:54 CEST,2/0,0,LOG,00000,"duration: 2.140 ms",,,,,,,,,"psql"
2010-07-21 22:13:04.594 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,9,"SELECT",2010-07-21 22:12:54 CEST,2/0,0,LOG,00000,"duration: 0.285 ms statement: select * from x;",,,,,,,,,"psql"
Esto es - si la consulta no será registrada por "log_statment" y sólo por log_min_duration_statement - será registradas como "duration:... ms statement: ...".
Aunque, si la consulta es registrada por los mecanismos de "log_statment" (como los create table o insert de arriba) - la línea registrada por log_min_duration_statment contendrá sólo la duración, y no la sentencia en sí misma. La razón es muy simple - no repetir la misma inforamción.
Esto desafortunadamente significa que si tú usas ambos log_statement y log_min_duration_statement - tú necesita alguna forma para unir estas líneas - con PID o session id. Cuando tú usas el registro normal stderr - tú necesitas añadir esta información de coincidencia a log_line_prefix, aunque cuando se usa csvlog - esto ya está allí.
Considerándolo todo - dominar estas configuraciones es la forma de comprender qué está ocurriendo con tu servidor. pg_stat_activity para comprobaciones rápidas de estado "aquí y ahora", y log_* para el análisis de largo plazo.
La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2010/07/22/logging-queries-how/
The translation may contain errors.
Una de las preguntas que saltan frecuentemente en el IRC es cómo ver las consultas que se ejecutan ahora en el servidor, y qué consultas lo fueron antes.
Teóricamente la respuesta a esto es simple - pg_stat_activity y log_min_duration_statement. O log_statment. ¿Cuál es la diferencia? Esto es exactamente por qué estoy escribiendo este post.
Lo primero de todo - para ver qué está ocurriendo en la base de datos justo ahora - tú puedes usar:
$ select * from pg_stat_activity ;
-[ RECORD 1 ]----+---------------------------------
datid | 16398
datname | depesz
procpid | 28765
usesysid | 16387
usename | depesz
application_name | psql
client_addr | [null]
client_port | -1
backend_start | 2010-07-21 15:44:08.017051+02
xact_start | 2010-07-21 15:46:13.92332+02
query_start | 2010-07-21 15:46:13.92332+02
waiting | f
current_query | select * from pg_stat_activity ;
La descripción exacta de qué es qué, tú la puedes encontrar en el bonito manual.
Hay un par de cosas importante, aunque:
current_query recorta las consultas largas a algún tamaño (no recuerdo cómo de grandes están ok, y es seguro que más grandes que las consultas usadas habitualmente, pero el límite existe)
A veces el campo "current_query" puede contener la cadena " - esto ocurre cuando tú estás consultando pg_stat_activvity desde no superusuario, y algunas consultas son ejecutadas por un usuario diferente que el usuario con el que tú has iniciado sesión.
Aparte de estos pequeños casos, esta es perfectamente la forma buena para ver el estado actual del sistema. Especialmente cuando añadiendo where para filtrar conexiones desocupadas. Mi consulta favorita para esta vista es:
SELECT
now() - query_start as runtime,
case when waiting then 'WAIT' else '' end as wait,
current_query
FROM
pg_stat_activity
WHERE
current_query <> '<IDLE>'
ORDER BY 1 DESC
Esto muestra las consultas que están trabajando, no desocupadas, con su correspondiente tiempo de ejecución, ordenadas por el tiempo de ejecución mayor, con información si la consulta está esperando por algo.
Ahora, ¿qué hay sobre ver todas las consultas?
Bien, nosotros necesitamos usar una de las GUCS (N. del T.: GUCS es el acrónimo de Grand Unified Configuration Setting): log_statement o log_min_duration_statement.
Lo primero, veamos log_statement. Puede tener 4 valores: none, ddl, mod y all.
Estos significan:
none - ninguna sentencia será registrada (por los mecanismos de log_statement - pueden aún ser registradas por alguna otra cosa)
ddl - sentencias como create, alter y drop serán registradas - es decir, todo lo que cambia el esquema de la base de datos
mod - registra todas las consultas que "ddl" registraría, más las sentencias insert, update, delete, truncate y "copy from"
all – registra todas las consultas
Hay también algunas observaciones importantes:
si tú llamas a una función (select function()) y ella internamente hace algunas modificaciones - no será registrado con log_statement <> all
las consultas son registradas antes de que ellas sean realmente ejecutadas (lo cual es muy guay, aunque es importante observar la diferencia desde la forma descrita abajo)
Vamos a ver cómo se muestra (estos son registros csv, desplázate a la derecha para ver las partes importantes):
2010-07-21 21:54:16.135 CEST,"depesz","depesz",18160,"[local]",4c475062.46f0,3,"idle",2010-07-21 21:54:10 CEST,2/4,0,LOG,00000,"statement: create table x (i int4);",,,,,,,,,"psql"
2010-07-21 21:54:21.344 CEST,"depesz","depesz",18160,"[local]",4c475062.46f0,4,"idle",2010-07-21 21:54:10 CEST,2/5,0,LOG,00000,"statement: insert into x (i) values (123);",,,,,,,,,"psql"
2010-07-21 21:54:24.094 CEST,"depesz","depesz",18160,"[local]",4c475062.46f0,5,"idle",2010-07-21 21:54:10 CEST,2/6,0,LOG,00000,"statement: select * from x;",,,,,,,,,"psql"
Y finalmente, log_min_duration_statement. Esta es (en mi opinión) la más útil de todas ellas. Si yo la activo (es decir, establecida a valor >=0), y ejecuto las mismas consultas, en los registros yo puedo ver:
2010-07-21 22:03:27.690 CEST,"depesz","depesz",18723,"[local]",4c475288.4923,4,"CREATE TABLE",2010-07-21 22:03:20 CEST,2/0,0,LOG,00000,"duration: 45.924 ms statement: create table x (i int4);",,,,,,,,,"psql"
2010-07-21 22:03:31.236 CEST,"depesz","depesz",18723,"[local]",4c475288.4923,5,"INSERT",2010-07-21 22:03:20 CEST,2/0,0,LOG,00000,"duration: 12.251 ms statement: insert into x (i) values (123);",,,,,,,,,"psql"
2010-07-21 22:03:33.724 CEST,"depesz","depesz",18723,"[local]",4c475288.4923,6,"SELECT",2010-07-21 22:03:20 CEST,2/0,0,LOG,00000,"duration: 0.307 ms statement: select * from x;",,,,,,,,,"psql"
Añadido importante: duration: ... elementos, que muestran cuanto tiempo tomó la sentencia.
Esto significa que las sentencias (y las duraciones) registradas por log_min_duration_statement pueden ser registradas sólo después de la ejecución. En la otra cara, log_min_duration te da la capacidad para registrar consultas que tomaron más allá de un tiempo definido - por ejemplo 5ms, o 15 segundos, así que tú puedes ajustarlo para registrar lo que es demasiado largo para tu aplicación.
Una nota sin embargo. Si tú activaras ambos log_statment (a algún valor) y log_min_duration_statement, y alguna consulta coincidiera en ambos casos, tú verás:
2010-07-21 22:12:58.423 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,5,"idle",2010-07-21 22:12:54 CEST,2/3,0,LOG,00000,"statement: create table x (i int4);",,,,,,,,,"psql"
2010-07-21 22:12:58.437 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,6,"CREATE TABLE",2010-07-21 22:12:54 CEST,2/0,0,LOG,00000,"duration: 14.017 ms",,,,,,,,,"psql"
2010-07-21 22:13:00.253 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,7,"idle",2010-07-21 22:12:54 CEST,2/4,0,LOG,00000,"statement: insert into x (i) values (123);",,,,,,,,,"psql"
2010-07-21 22:13:00.255 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,8,"INSERT",2010-07-21 22:12:54 CEST,2/0,0,LOG,00000,"duration: 2.140 ms",,,,,,,,,"psql"
2010-07-21 22:13:04.594 CEST,"depesz","depesz",19197,"[local]",4c4754c6.4afd,9,"SELECT",2010-07-21 22:12:54 CEST,2/0,0,LOG,00000,"duration: 0.285 ms statement: select * from x;",,,,,,,,,"psql"
Esto es - si la consulta no será registrada por "log_statment" y sólo por log_min_duration_statement - será registradas como "duration:... ms statement: ...".
Aunque, si la consulta es registrada por los mecanismos de "log_statment" (como los create table o insert de arriba) - la línea registrada por log_min_duration_statment contendrá sólo la duración, y no la sentencia en sí misma. La razón es muy simple - no repetir la misma inforamción.
Esto desafortunadamente significa que si tú usas ambos log_statement y log_min_duration_statement - tú necesita alguna forma para unir estas líneas - con PID o session id. Cuando tú usas el registro normal stderr - tú necesitas añadir esta información de coincidencia a log_line_prefix, aunque cuando se usa csvlog - esto ya está allí.
Considerándolo todo - dominar estas configuraciones es la forma de comprender qué está ocurriendo con tu servidor. pg_stat_activity para comprobaciones rápidas de estado "aquí y ahora", y log_* para el análisis de largo plazo.
domingo, 7 de agosto de 2016
Esperando a 9.0 -- WAITING FOR 9.0 – PG_UPGRADE
Esta entrada es una traducción de https://www.depesz.com/2010/05/19/waiting-for-9-0-pg_upgrade/
La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2010/05/19/waiting-for-9-0-pg_upgrade/
The translation may contain errors.
El 12 de mayo, Bruce Monjian subió un nuevo módulo de contribución para la 9.0 - pg_upgrade.
Según entiendo - esto es lo que estaba disponible antes como pg-migrator.
Si tú no estás familiarizado con ello - es una herramienta que permite hacer un upgrade (subir versión) de $PGDATA desde alguna versión a otra versión. ¿Cuál es el caso de uso? Asumamos que tú tienes esta base de datos de 200 GB funcionando en 8.3, y te gustaría ir a 8.4 (o 9.0). El camino normal es pg_dump + pg_restore - el cual llevará algún tiempo. Con pg-migrate/pg_upgrade esto debe de ser más rápido, y más fácil. Así, vamos a jugar con ello.
Yo tengo 2 versiones de Pg instaladas:
8.3.10
9.0 (directo desde git, se presenta a sí misma como 9.0beta1)
Lo primero, vamos a crear una base de datos pruebas en 8.3. Como yo no tengo la base de datos aún (es una instalación de pruebas), yo crearé una:
=$ source pg-env.sh 8.3.10
Pg version 8.3.10 chosen
=$ mkdir /home/pgdba/data-8.3
=$ initdb -D /home/pgdba/data-8.3/ -E UTF-8
...
Success. You can now start the database server using:
...
=$ pg_ctl -D /home/pgdba/data-8.3 -l /home/pgdba/logfile-8.3 start
server starting
OK, aquí yo tengo una buena 8.3 funcionando:
=$ psql -d postgres -c 'select version()'
version
--------------------------------------------------------------------------------------------------
PostgreSQL 8.3.10 on x86_64-unknown-linux-gnu, compiled by GCC gcc (Ubuntu 4.4.3-4ubuntu5) 4.4.3
(1 row)
Así vamos a añadir algunos datos a ella:
# create table test ( i int4, j int8, t text, ts timestamptz, ip inet);
CREATE TABLE
# insert into test (i, j, t, ts, ip)
select
random() * 1000000000,
random() * 8000000000,
repeat('depesz : ', cast(5 + random() * 10 as int4)),
now() - random() * '5 years'::interval,
'127.0.0.1'
from generate_series(1, 10000000);
INSERT 0 10000000
OK. Datos dentro, vamos a ver los datos y algunas estadísticas, para ser capaz de verificar los datos después de la migración:
<code># select * from test limit 3;
i | j | t | ts | ip
-----------+------------+--------------------------------------------------------------------------------------------------------------+-------------------------------+-----------
154912674 | 7280213505 | depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : | 2007-07-25 20:55:11.357501+02 | 127.0.0.1
560106405 | 7676185891 | depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : | 2006-07-23 15:40:35.203901+02 | 127.0.0.1
683442113 | 5831204534 | depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : | 2006-07-01 16:58:17.175101+02 | 127.0.0.1
(3 rows)</code>
# select
min(i), count(distinct i), max(i), sum(i),
min(j), count(distinct j), max(j), sum(j),
count(distinct t), sum(length(t)),
count(distinct ts),
count(*),
pg_relation_size('test'),
pg_total_relation_size('test')
from test;
-[ RECORD 1 ]------------------------------
min | 16
count | 9948511
max | 999999620
sum | 5001298277187874
min | 417
count | 9976964
max | 7999999207
sum | 40006841224204502
count | 11
sum | 900027558
count | 9968978
count | 10000000
pg_relation_size | 1563410432
pg_total_relation_size | 1563418624
OK, Ahora, vamos a añadir algunos índices para estar seguros que estos están también funcionando después de la migración:
# create index i1 on test (i);
CREATE INDEX
# create index i2 on test (j);
CREATE INDEX
# create index i3 on test (ts);
CREATE INDEX
# select min(i), max(i), min(j), max(j), min(ts), max(ts) from test;
-[ RECORD 1 ]----------------------
min | 16
max | 999999620
min | 417
max | 7999999207
min | 2005-05-13 15:03:01.027901+02
max | 2010-05-12 15:02:48.586301+02
# explain analyze select min(i), max(i), min(j), max(j), min(ts), max(ts) from test;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Result (cost=22.35..22.36 rows=1 width=0) (actual time=0.113..0.113 rows=1 loops=1)
InitPlan
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.023..0.023 rows=1 loops=1)
-> Index Scan using i1 on test (cost=0.00..37258844.64 rows=10000000 width=20) (actual time=0.022..0.022 rows=1 loops=1)
Filter: (i IS NOT NULL)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.008..0.008 rows=1 loops=1)
-> Index Scan Backward using i1 on test (cost=0.00..37258844.64 rows=10000000 width=20) (actual time=0.007..0.007 rows=1 loops=1)
Filter: (i IS NOT NULL)
-> Limit (cost=0.00..3.72 rows=1 width=20) (actual time=0.012..0.012 rows=1 loops=1)
-> Index Scan using i2 on test (cost=0.00..37236683.21 rows=10000000 width=20) (actual time=0.011..0.011 rows=1 loops=1)
Filter: (j IS NOT NULL)
-> Limit (cost=0.00..3.72 rows=1 width=20) (actual time=0.006..0.006 rows=1 loops=1)
-> Index Scan Backward using i2 on test (cost=0.00..37236683.21 rows=10000000 width=20) (actual time=0.006..0.006 rows=1 loops=1)
Filter: (j IS NOT NULL)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.049..0.049 rows=1 loops=1)
-> Index Scan using i3 on test (cost=0.00..37257725.52 rows=10000000 width=20) (actual time=0.048..0.048 rows=1 loops=1)
Filter: (ts IS NOT NULL)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.008..0.008 rows=1 loops=1)
-> Index Scan Backward using i3 on test (cost=0.00..37257725.52 rows=10000000 width=20) (actual time=0.007..0.007 rows=1 loops=1)
Filter: (ts IS NOT NULL)
Total runtime: 0.192 ms
(21 rows)
OK. Todo parece estár funcionando. Antes de que yo realmente pruebe a migrarla, yo primero haré un backup del $PGDATA de 8.3 - sólo para estar seguro de que yo no tengo que re-generar los datos.
=$ pg_ctl -D /home/pgdba/data-8.3/ stop
waiting for server to shut down.... done
server stopped
=$ rsync -a --delete --delete-after data-8.3/ data-8.3.backup/
=$ for a in data-8.3*; do printf "%-30s : " $a; find $a/ -type f -print | sort | xargs cat | md5sum -; done
data-8.3 : a559d351b54f20ce66a0bb89a0724eb9 -
data-8.3.backup : a559d351b54f20ce66a0bb89a0724eb9 -
Así, no vamos a intentar actualizarla a 9.0. Según la documentación yo necesito primero crear el cluster de destino. Así, vamos a hacerlo:
=$ source pg-env.sh 9.0
Pg version 9.0 chosen
=$ initdb -D /home/pgdba/data-9.0
...
Success. You can now start the database server using:
Antes de que yo vaya, vamos a comprobar el md5sum de data-9.0:
=$ for a in data-9.0; do printf "%-30s : " $a; find $a/ -type f -print | sort | xargs cat | md5sum -; done
data-9.0 : 930fdef9c4c48808a9dbabe8573b2d2c -
Ahora, que yo tengo ambos directorio de datos listos, y ninguno de los pg ejecutándose (ellos no pueden estar ejecutándose durante el upgrade, yo puedo:
=$ time pg_upgrade
--old-datadir=/home/pgdba/data-8.3/ \
--new-datadir=/home/pgdba/data-9.0/ \
--old-bindir=/opt/pgsql-8.3.10/bin/ \
--new-bindir=/opt/pgsql-9.0/bin/ \
--old-port=5830 \
--new-port=5900 \
--user=pgdba
Performing Consistency Checks
-----------------------------
Checking old data directory (/home/pgdba/data-8.3) ok
Checking new data directory (/home/pgdba/data-9.0) ok
Checking for /contrib/isn with bigint-passing mismatch ok
Checking for invalid 'name' user columns ok
Checking for tsquery user columns ok
Creating script to adjust sequences ok
Checking for large objects ok
Creating catalog dump ok
Checking for presence of required libraries ok
| If pg_upgrade fails after this point, you must
| re-initdb the new cluster before continuing.
| You will also need to remove the ".old" suffix
| from /home/pgdba/data-8.3/global/pg_control.old.
Performing Migration
--------------------
Adding ".old" suffix to old global/pg_control ok
Analyzing all rows in the new cluster ok
Freezing all rows on the new cluster ok
Deleting new commit clogs ok
Copying old commit clogs to new server ok
Setting next transaction id for new cluster ok
Resetting WAL archives ok
Setting frozenxid counters in new cluster ok
Creating databases in the new cluster ok
Adding support functions to new cluster ok
Restoring database schema to new cluster ok
Removing support functions from new cluster ok
Restoring user relation files
ok
Setting next oid for new cluster ok
Creating script to delete old cluster ok
Checking for tsvector user columns ok
Checking for hash and gin indexes ok
Checking for bpchar_pattern_ops indexes ok
Checking for large objects ok
Upgrade complete
----------------
| Optimizer statistics and free space information
| are not transferred by pg_upgrade so consider
| running:
| vacuumdb --all --analyze
| on the newly-upgraded cluster.
| Running this script will delete the old cluster's data files:
| /home/pgdba/pg_upgrade_output/delete_old_cluster.sh
real 0m28.910s
user 0m0.160s
sys 0m5.660s
Comprobación rápida:
=$ for a in data-8.3* data-9.0; do printf "%-30s : " $a; find $a/ -type f -print | sort | xargs cat | md5sum -; done
data-8.3 : 2d3e26f3e7363ec225fb1f9f93e45184 -
data-8.3.backup : a559d351b54f20ce66a0bb89a0724eb9 -
data-9.0 : 40ccb32c89acafb5436ea7dcd9f737a5 -
Muetra que ambos fuente y destinos han sido modificados. Así, vamos a arrancar la 9.0 y ver los datos:
=$ pg_ctl -D /home/pgdba/data-9.0 -l logfile-9.0 start
server starting
Por supuesto - yo debo de ejecutar vacuum como sugerido por pg_upgrade:
=$ vacuumdb --all --analyze
vacuumdb: vacuuming database "postgres"
WARNING: some databases have not been vacuumed in over 2 billion transactions
DETAIL: You might have already suffered transaction-wraparound data loss.
vacuumdb: vacuuming database "template1"
WARNING: some databases have not been vacuumed in over 2 billion transactions
DETAIL: You might have already suffered transaction-wraparound data loss.
El error de arriba parece malo, pero esto ha sido recientemente discutivo en pgsql-hackers, y yo creo que será corregido antes de la 9.0 final sea liberada.
¿Qué hay acerca de nuestros datos reales?
# select
min(i), count(distinct i), max(i), sum(i),
min(j), count(distinct j), max(j), sum(j),
count(distinct t), sum(length(t)),
count(distinct ts),
count(*),
pg_relation_size('test'),
pg_total_relation_size('test')
from test;
-[ RECORD 1 ]----------+------------------
min | 16
count | 9948511
max | 999999620
sum | 5001298277187874
min | 417
count | 9976964
max | 7999999207
sum | 40006841224204502
count | 11
sum | 900027558
count | 9968978
count | 10000000
pg_relation_size | 1563410432
pg_total_relation_size | 2237767680
Todos los valores son los mismos excepto para pg_total_relation_size, pero estos es porque yo añadí índices en 8.3 antes de obtener pg_total_relation_size(), así que está bien.
Ahora. ¿Serán usados los índices?
# explain analyze select min(i), max(i), min(j), max(j), min(ts), max(ts) from test;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Result (cost=22.36..22.37 rows=1 width=0) (actual time=0.319..0.319 rows=1 loops=1)
InitPlan 1 (returns $0)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.066..0.077 rows=1 loops=1)
-> Index Scan using i1 on test (cost=0.00..37258941.16 rows=10000000 width=20) (actual time=0.039..0.039 rows=1 loops=1)
Index Cond: (i IS NOT NULL)
InitPlan 2 (returns $1)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.042..0.051 rows=1 loops=1)
-> Index Scan Backward using i1 on test (cost=0.00..37258941.16 rows=10000000 width=20) actual time=0.023..0.023 rows=1 loops=1)
Index Cond: (i IS NOT NULL)
InitPlan 3 (returns $2)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.039..0.046 rows=1 loops=1)
-> Index Scan using i2 on test (cost=0.00..37258751.12 rows=10000000 width=20) (actual time=0.025..0.025 rows=1 loops=1)
Index Cond: (j IS NOT NULL)
InitPlan 4 (returns $3)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.031..0.037 rows=1 loops=1)
-> Index Scan Backward using i2 on test (cost=0.00..37258751.12 rows=10000000 width=20) (actual time=0.018..0.018 rows=1 loops=1)
Index Cond: (j IS NOT NULL)
InitPlan 5 (returns $4)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.016..0.017 rows=1 loops=1)
-> Index Scan using i3 on test (cost=0.00..37259259.58 rows=10000000 width=20) (actual time=0.015..0.015 rows=1 loops=1)
Index Cond: (ts IS NOT NULL)
InitPlan 6 (returns $5)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.009..0.009 rows=1 loops=1)
-> Index Scan Backward using i3 on test (cost=0.00..37259259.58 rows=10000000 width=20) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (ts IS NOT NULL)
Total runtime: 0.403 ms
(26 rows)
Sí. Funciona.
Actualmente hay algunos cortes ásperos, a saber:
algo sobre transaction wraparound y template0
falta de documentación en formato html
pero yo creo que esto será pronto corregido. Y la velocidad es muy impresionante - 2.2 GB de $PGDATA convertidos en 29 segundos es muy guay.
La traducción puede contener errores.
This entry is a translation of https://www.depesz.com/2010/05/19/waiting-for-9-0-pg_upgrade/
The translation may contain errors.
El 12 de mayo, Bruce Monjian subió un nuevo módulo de contribución para la 9.0 - pg_upgrade.
Según entiendo - esto es lo que estaba disponible antes como pg-migrator.
Si tú no estás familiarizado con ello - es una herramienta que permite hacer un upgrade (subir versión) de $PGDATA desde alguna versión a otra versión. ¿Cuál es el caso de uso? Asumamos que tú tienes esta base de datos de 200 GB funcionando en 8.3, y te gustaría ir a 8.4 (o 9.0). El camino normal es pg_dump + pg_restore - el cual llevará algún tiempo. Con pg-migrate/pg_upgrade esto debe de ser más rápido, y más fácil. Así, vamos a jugar con ello.
Yo tengo 2 versiones de Pg instaladas:
8.3.10
9.0 (directo desde git, se presenta a sí misma como 9.0beta1)
Lo primero, vamos a crear una base de datos pruebas en 8.3. Como yo no tengo la base de datos aún (es una instalación de pruebas), yo crearé una:
=$ source pg-env.sh 8.3.10
Pg version 8.3.10 chosen
=$ mkdir /home/pgdba/data-8.3
=$ initdb -D /home/pgdba/data-8.3/ -E UTF-8
...
Success. You can now start the database server using:
...
=$ pg_ctl -D /home/pgdba/data-8.3 -l /home/pgdba/logfile-8.3 start
server starting
OK, aquí yo tengo una buena 8.3 funcionando:
=$ psql -d postgres -c 'select version()'
version
--------------------------------------------------------------------------------------------------
PostgreSQL 8.3.10 on x86_64-unknown-linux-gnu, compiled by GCC gcc (Ubuntu 4.4.3-4ubuntu5) 4.4.3
(1 row)
Así vamos a añadir algunos datos a ella:
# create table test ( i int4, j int8, t text, ts timestamptz, ip inet);
CREATE TABLE
# insert into test (i, j, t, ts, ip)
select
random() * 1000000000,
random() * 8000000000,
repeat('depesz : ', cast(5 + random() * 10 as int4)),
now() - random() * '5 years'::interval,
'127.0.0.1'
from generate_series(1, 10000000);
INSERT 0 10000000
OK. Datos dentro, vamos a ver los datos y algunas estadísticas, para ser capaz de verificar los datos después de la migración:
<code># select * from test limit 3;
i | j | t | ts | ip
-----------+------------+--------------------------------------------------------------------------------------------------------------+-------------------------------+-----------
154912674 | 7280213505 | depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : | 2007-07-25 20:55:11.357501+02 | 127.0.0.1
560106405 | 7676185891 | depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : | 2006-07-23 15:40:35.203901+02 | 127.0.0.1
683442113 | 5831204534 | depesz : depesz : depesz : depesz : depesz : depesz : depesz : depesz : | 2006-07-01 16:58:17.175101+02 | 127.0.0.1
(3 rows)</code>
# select
min(i), count(distinct i), max(i), sum(i),
min(j), count(distinct j), max(j), sum(j),
count(distinct t), sum(length(t)),
count(distinct ts),
count(*),
pg_relation_size('test'),
pg_total_relation_size('test')
from test;
-[ RECORD 1 ]------------------------------
min | 16
count | 9948511
max | 999999620
sum | 5001298277187874
min | 417
count | 9976964
max | 7999999207
sum | 40006841224204502
count | 11
sum | 900027558
count | 9968978
count | 10000000
pg_relation_size | 1563410432
pg_total_relation_size | 1563418624
OK, Ahora, vamos a añadir algunos índices para estar seguros que estos están también funcionando después de la migración:
# create index i1 on test (i);
CREATE INDEX
# create index i2 on test (j);
CREATE INDEX
# create index i3 on test (ts);
CREATE INDEX
# select min(i), max(i), min(j), max(j), min(ts), max(ts) from test;
-[ RECORD 1 ]----------------------
min | 16
max | 999999620
min | 417
max | 7999999207
min | 2005-05-13 15:03:01.027901+02
max | 2010-05-12 15:02:48.586301+02
# explain analyze select min(i), max(i), min(j), max(j), min(ts), max(ts) from test;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Result (cost=22.35..22.36 rows=1 width=0) (actual time=0.113..0.113 rows=1 loops=1)
InitPlan
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.023..0.023 rows=1 loops=1)
-> Index Scan using i1 on test (cost=0.00..37258844.64 rows=10000000 width=20) (actual time=0.022..0.022 rows=1 loops=1)
Filter: (i IS NOT NULL)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.008..0.008 rows=1 loops=1)
-> Index Scan Backward using i1 on test (cost=0.00..37258844.64 rows=10000000 width=20) (actual time=0.007..0.007 rows=1 loops=1)
Filter: (i IS NOT NULL)
-> Limit (cost=0.00..3.72 rows=1 width=20) (actual time=0.012..0.012 rows=1 loops=1)
-> Index Scan using i2 on test (cost=0.00..37236683.21 rows=10000000 width=20) (actual time=0.011..0.011 rows=1 loops=1)
Filter: (j IS NOT NULL)
-> Limit (cost=0.00..3.72 rows=1 width=20) (actual time=0.006..0.006 rows=1 loops=1)
-> Index Scan Backward using i2 on test (cost=0.00..37236683.21 rows=10000000 width=20) (actual time=0.006..0.006 rows=1 loops=1)
Filter: (j IS NOT NULL)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.049..0.049 rows=1 loops=1)
-> Index Scan using i3 on test (cost=0.00..37257725.52 rows=10000000 width=20) (actual time=0.048..0.048 rows=1 loops=1)
Filter: (ts IS NOT NULL)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.008..0.008 rows=1 loops=1)
-> Index Scan Backward using i3 on test (cost=0.00..37257725.52 rows=10000000 width=20) (actual time=0.007..0.007 rows=1 loops=1)
Filter: (ts IS NOT NULL)
Total runtime: 0.192 ms
(21 rows)
OK. Todo parece estár funcionando. Antes de que yo realmente pruebe a migrarla, yo primero haré un backup del $PGDATA de 8.3 - sólo para estar seguro de que yo no tengo que re-generar los datos.
=$ pg_ctl -D /home/pgdba/data-8.3/ stop
waiting for server to shut down.... done
server stopped
=$ rsync -a --delete --delete-after data-8.3/ data-8.3.backup/
=$ for a in data-8.3*; do printf "%-30s : " $a; find $a/ -type f -print | sort | xargs cat | md5sum -; done
data-8.3 : a559d351b54f20ce66a0bb89a0724eb9 -
data-8.3.backup : a559d351b54f20ce66a0bb89a0724eb9 -
Así, no vamos a intentar actualizarla a 9.0. Según la documentación yo necesito primero crear el cluster de destino. Así, vamos a hacerlo:
=$ source pg-env.sh 9.0
Pg version 9.0 chosen
=$ initdb -D /home/pgdba/data-9.0
...
Success. You can now start the database server using:
Antes de que yo vaya, vamos a comprobar el md5sum de data-9.0:
=$ for a in data-9.0; do printf "%-30s : " $a; find $a/ -type f -print | sort | xargs cat | md5sum -; done
data-9.0 : 930fdef9c4c48808a9dbabe8573b2d2c -
Ahora, que yo tengo ambos directorio de datos listos, y ninguno de los pg ejecutándose (ellos no pueden estar ejecutándose durante el upgrade, yo puedo:
=$ time pg_upgrade
--old-datadir=/home/pgdba/data-8.3/ \
--new-datadir=/home/pgdba/data-9.0/ \
--old-bindir=/opt/pgsql-8.3.10/bin/ \
--new-bindir=/opt/pgsql-9.0/bin/ \
--old-port=5830 \
--new-port=5900 \
--user=pgdba
Performing Consistency Checks
-----------------------------
Checking old data directory (/home/pgdba/data-8.3) ok
Checking new data directory (/home/pgdba/data-9.0) ok
Checking for /contrib/isn with bigint-passing mismatch ok
Checking for invalid 'name' user columns ok
Checking for tsquery user columns ok
Creating script to adjust sequences ok
Checking for large objects ok
Creating catalog dump ok
Checking for presence of required libraries ok
| If pg_upgrade fails after this point, you must
| re-initdb the new cluster before continuing.
| You will also need to remove the ".old" suffix
| from /home/pgdba/data-8.3/global/pg_control.old.
Performing Migration
--------------------
Adding ".old" suffix to old global/pg_control ok
Analyzing all rows in the new cluster ok
Freezing all rows on the new cluster ok
Deleting new commit clogs ok
Copying old commit clogs to new server ok
Setting next transaction id for new cluster ok
Resetting WAL archives ok
Setting frozenxid counters in new cluster ok
Creating databases in the new cluster ok
Adding support functions to new cluster ok
Restoring database schema to new cluster ok
Removing support functions from new cluster ok
Restoring user relation files
ok
Setting next oid for new cluster ok
Creating script to delete old cluster ok
Checking for tsvector user columns ok
Checking for hash and gin indexes ok
Checking for bpchar_pattern_ops indexes ok
Checking for large objects ok
Upgrade complete
----------------
| Optimizer statistics and free space information
| are not transferred by pg_upgrade so consider
| running:
| vacuumdb --all --analyze
| on the newly-upgraded cluster.
| Running this script will delete the old cluster's data files:
| /home/pgdba/pg_upgrade_output/delete_old_cluster.sh
real 0m28.910s
user 0m0.160s
sys 0m5.660s
Comprobación rápida:
=$ for a in data-8.3* data-9.0; do printf "%-30s : " $a; find $a/ -type f -print | sort | xargs cat | md5sum -; done
data-8.3 : 2d3e26f3e7363ec225fb1f9f93e45184 -
data-8.3.backup : a559d351b54f20ce66a0bb89a0724eb9 -
data-9.0 : 40ccb32c89acafb5436ea7dcd9f737a5 -
Muetra que ambos fuente y destinos han sido modificados. Así, vamos a arrancar la 9.0 y ver los datos:
=$ pg_ctl -D /home/pgdba/data-9.0 -l logfile-9.0 start
server starting
Por supuesto - yo debo de ejecutar vacuum como sugerido por pg_upgrade:
=$ vacuumdb --all --analyze
vacuumdb: vacuuming database "postgres"
WARNING: some databases have not been vacuumed in over 2 billion transactions
DETAIL: You might have already suffered transaction-wraparound data loss.
vacuumdb: vacuuming database "template1"
WARNING: some databases have not been vacuumed in over 2 billion transactions
DETAIL: You might have already suffered transaction-wraparound data loss.
El error de arriba parece malo, pero esto ha sido recientemente discutivo en pgsql-hackers, y yo creo que será corregido antes de la 9.0 final sea liberada.
¿Qué hay acerca de nuestros datos reales?
# select
min(i), count(distinct i), max(i), sum(i),
min(j), count(distinct j), max(j), sum(j),
count(distinct t), sum(length(t)),
count(distinct ts),
count(*),
pg_relation_size('test'),
pg_total_relation_size('test')
from test;
-[ RECORD 1 ]----------+------------------
min | 16
count | 9948511
max | 999999620
sum | 5001298277187874
min | 417
count | 9976964
max | 7999999207
sum | 40006841224204502
count | 11
sum | 900027558
count | 9968978
count | 10000000
pg_relation_size | 1563410432
pg_total_relation_size | 2237767680
Todos los valores son los mismos excepto para pg_total_relation_size, pero estos es porque yo añadí índices en 8.3 antes de obtener pg_total_relation_size(), así que está bien.
Ahora. ¿Serán usados los índices?
# explain analyze select min(i), max(i), min(j), max(j), min(ts), max(ts) from test;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Result (cost=22.36..22.37 rows=1 width=0) (actual time=0.319..0.319 rows=1 loops=1)
InitPlan 1 (returns $0)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.066..0.077 rows=1 loops=1)
-> Index Scan using i1 on test (cost=0.00..37258941.16 rows=10000000 width=20) (actual time=0.039..0.039 rows=1 loops=1)
Index Cond: (i IS NOT NULL)
InitPlan 2 (returns $1)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.042..0.051 rows=1 loops=1)
-> Index Scan Backward using i1 on test (cost=0.00..37258941.16 rows=10000000 width=20) actual time=0.023..0.023 rows=1 loops=1)
Index Cond: (i IS NOT NULL)
InitPlan 3 (returns $2)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.039..0.046 rows=1 loops=1)
-> Index Scan using i2 on test (cost=0.00..37258751.12 rows=10000000 width=20) (actual time=0.025..0.025 rows=1 loops=1)
Index Cond: (j IS NOT NULL)
InitPlan 4 (returns $3)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.031..0.037 rows=1 loops=1)
-> Index Scan Backward using i2 on test (cost=0.00..37258751.12 rows=10000000 width=20) (actual time=0.018..0.018 rows=1 loops=1)
Index Cond: (j IS NOT NULL)
InitPlan 5 (returns $4)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.016..0.017 rows=1 loops=1)
-> Index Scan using i3 on test (cost=0.00..37259259.58 rows=10000000 width=20) (actual time=0.015..0.015 rows=1 loops=1)
Index Cond: (ts IS NOT NULL)
InitPlan 6 (returns $5)
-> Limit (cost=0.00..3.73 rows=1 width=20) (actual time=0.009..0.009 rows=1 loops=1)
-> Index Scan Backward using i3 on test (cost=0.00..37259259.58 rows=10000000 width=20) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (ts IS NOT NULL)
Total runtime: 0.403 ms
(26 rows)
Sí. Funciona.
Actualmente hay algunos cortes ásperos, a saber:
algo sobre transaction wraparound y template0
falta de documentación en formato html
pero yo creo que esto será pronto corregido. Y la velocidad es muy impresionante - 2.2 GB de $PGDATA convertidos en 29 segundos es muy guay.
Suscribirse a:
Entradas (Atom)